Afropean: Notes from Black Europe (2019)
Johny Pitts
Johny Pitts is a photographer and writer who lives in the north of England who set out to explore "black Europe from the street up" those districts within European cities that, although they were once 'white spaces' in the past, they are now occupied by Black people. Unhappy with the framing of the Black experience back home in post-industrial Sheffield, Pitts decided to become a nomad and goes abroad to seek out the sense of belonging he cannot find in post-Brexit Britain, and Afropean details his journey through Paris, Brussels, Lisbon, Berlin, Stockholm and Moscow.
However, Pitts isn't just avoiding the polarisation and structural racism embedded in contemporary British life. Rather, he is seeking a kind of super-national community that transcends the reductive and limiting nationalisms of all European countries, most of which have based their national story on a self-serving mix of nostalgia and postcolonial fairy tales.
Indeed, the term 'Afropean' is the key to understanding the goal of this captivating memoir. Pitts writes at the beginning of this book that the word wasn't driven only as a response to the crude nativisms of Nigel Farage and Marine Le Pen, but that it:
encouraged me to think of myself as whole and unhyphenated. [ ] Here was a space where blackness was taking part in shaping European identity at large. It suggested the possibility of living in and with more than one idea: Africa and Europe, or, by extension, the Global South and the West, without being mixed-this, half-that or black-other. That being black in Europe didn t necessarily mean being an immigrant.
In search of this whole new theory of home, Pitts travels to the infamous banlieue of Clichy-sous-Bois just to the East of Paris, thence to Matong in Brussels, as well as a quick and abortive trip into Moscow and other parallel communities throughout the continent. In these disparate environs, Pitts strikes up countless conversations with regular folk in order to hear their quotidian stories of living, and ultimately to move away from the idea that Black history is defined exclusively by slavery. Indeed, to Pitts, the idea of race is one that ultimately restricts one's humanity; the concept "is often forced to embody and speak for certain ideas, despite the fact it can't ever hold in both hands the full spectrum of a human life and the cultural nuances it creates." It's difficult to do justice to the effectiveness of the conversations Pitts has throughout his travels, but his shrewd attention to demeanour, language, raiment and expression vividly brings alive the people he talks to. Of related interest to fellow Brits as well are the many astute observations and comparisons with Black and working-class British life.
The tone shifts quite often throughout this book. There might be an amusing aside one minute, such as the portrait of an African American tourist in Paris to whom "the whole city was a film set, with even its homeless people appearing to him as something oddly picturesque." But the register abruptly changes when he visits Clichy-sous-Bois on an anniversary of important to the area, and an element of genuine danger is introduced when Johny briefly visits Moscow and barely gets out alive.
What's especially remarkable about this book is there is a freshness to Pitt s treatment of many well-worn subjects. This can be seen in his account of Belgium under the reign of Leopold II, the history of Portuguese colonialism (actually mostly unknown to me), as well in the way Pitts' own attitude to contemporary anti-fascist movements changes throughout an Antifa march. This chapter was an especial delight, and not only because it underlined just how much of Johny's trip was an inner journey of an author willing have his mind changed.
Although Johny travels alone throughout his journey, in the second half of the book, Pitts becomes increasingly accompanied by a number of Black intellectuals by the selective citing of Frantz Fanon and James Baldwin and Caryl Phillips. (Nevertheless, Jonny has also brought his camera for the journey as well, adding a personal touch to this already highly-intimate book.) I suspect that his increasing exercise of Black intellectual writing in the latter half of the book may be because Pitts' hopes about 'Afropean' existence ever becoming a reality are continually dashed and undercut. The unity among potential Afropeans appears more-and-more unrealisable as the narrative unfolds, the various reasons of which Johny explores both prosaically and poetically.
Indeed, by the end of the book, it's unclear whether Johny has managed to find what he left the shores of England to find. But his mix of history, sociology and observation of other cultures right on my doorstep was something of a revelation to me.
Orwell's Roses (2021)
Rebecca SolnitOrwell s Roses is an alternative journey through the life and afterlife of George Orwell, reimaging his life primarily through the lens of his attentiveness to nature. Yet this framing of the book as an 'alternative' history is only revisionist if we compare it to the usual view of Orwell as a bastion of 'free speech' and English 'common sense' the roses of the title of this book were very much planted by Orwell in his Hertfordshire garden in 1936, and his yearning of nature one was one of the many constants throughout his life. Indeed, Orwell wrote about wildlife and outdoor life whenever he could get away with it, taking pleasure in a blackbird's song and waxing nostalgically about the English countryside in his 1939 novel Coming Up for Air (reviewed yesterday).
By sheer chance, I actually visited this exact garden immediately to the publication of this book
Solnit has a particular ability to evince unexpected connections between Orwell and the things he was writing about: Joseph Stalin's obsession with forcing lemons to grow in ludicrously cold climates; Orwell s slave-owning ancestors in Jamaica; Jamaica Kincaid's critique of colonialism in the flower garden; and the exploitative rose industry in Colombia that supplies the American market. Solnit introduces all of these new correspondences in a voice that feels like a breath of fresh air after decades of stodgy Orwellania, and without lapsing into a kind of verbal soft-focus. Indeed, the book displays a marked indifference towards the usual (male-centric) Orwell fandom.
Her book draws to a close with a rereading of the 'dystopian' Nineteen Eighty-Four that completes her touching portrait of a more optimistic and hopeful Orwell, as well as a reflection on beauty and a manifesto for experiencing joy as an act of resistance.
The Disaster Artist (2013)
Greg Sestero & Tom Bissell
For those not already in the know, The Room was a 2003 film by director-producer-writer-actor Tommy Wiseau, an inscrutable Polish immigr with an impenetrable background, an idiosyncratic choice of wardrobe and a mysterious large source of income. The film, which centres on a melodramatic love triangle, has since been described by several commentators and publications as one of the worst films ever made.
Tommy's production completely bombed at the so-called 'box office' (the release was actually funded entirely by Wiseau personally), but the film slowly became a favourite at cult cinema screenings. Given Tommy's prominent and central role in the film, there was always an inherent cruelty involved in indulging in the spectacle of The Room the audience was laughing because the film was astonishingly bad, of course, but Wiseau infused his film with sincere earnestness that in a heartless twist of irony may be precisely why it is so terrible to begin with. Indeed, it should be stressed that The Room is not simply a 'bad' film, and therefore not worth paying any attention to: it is uncannily bad in a way that makes it eerily compelling to watch. It unintentionally subverts all the rules of filmmaking in a way that captivates the attention. Take this representative example:
This thirty-six-second scene showcases almost every problem in The Room: the acting, the lighting, the sound design, the pacing, the dialogue and that this unnecessary scene (which does not advance the plot) even exists in the first place.
One problem that the above clip doesn't capture, however, is Tommy's vulnerable ego. (He would later make the potentially conflicting claims that The Room was both an ironic cult success and that he is okay with people interpreting it sincerely). Indeed, the filmmaker's central role as Johnny (along with his Willy-Wonka meets Dracula persona) doesn't strike viewers as yet another vanity project, it actually asks more questions than it answers. Why did Tommy even make this film? What is driving him psychologically? And why and how? is he so spellbinding?
On the surface, then, 2013's The Disaster Artist is a book about the making of one the strangest films ever made, written by The Room's co-star Greg Sestero and journalist Tom Bissell. Naturally, you learn some jaw-dropping facts about the production and inspiration of the film, the seed of which was planted when Greg and Tommy went to see an early screening of The Talented Mr Ripley (1999). It turns out that Greg's character in The Room is based on Tommy's idiosyncratic misinterpretation of its plot, extending even to the character's name Mark who, in textbook Tommy style, was taken directly (or at least Tommy believed) from one of Ripley's movie stars: "Mark Damon" [sic].
Almost as absorbing as The Room itself, The Disaster Artist is partly a memoir about Thomas P. Wiseau and his cinematic masterpiece. But it could also be described as a biography about a dysfunctional male relationship and, almost certainly entirely unconsciously, a text about the limitations of hetronormativity. It is this latter element that struck me the most whilst reading this book: if you take a step back for a moment, there is something uniquely sad about Tommy's inability to connect with others, and then, when Wiseau poured his soul into his film people just laughed. Despite the stories about his atrocious behaviour both on and off the film set, there's something deeply tragic about the whole affair.
Jean-Luc Godard, who passed away earlier this year, once observed that every fictional film is a documentary of its actors. The Disaster Artist shows that this well-worn aphorism doesn't begin to cover it.
Welcome to yet another report from the Reproducible Builds project, this time for November 2022. In all of these reports (which we have been publishing regularly since May 2015) we attempt to outline the most important things that we have been up to over the past month. As always, if you interested in contributing to the project, please visit our Contribute page on our website.
Reproducible Builds Summit 2022
Following-up from last month s report about our recent summit in Venice, Italy, a comprehensive report from the meeting has not been finalised yet watch this space!
As a very small preview, however, we can link to several issues that were filed about the website during the summit (#38, #39, #40, #41, #42, #43, etc.) and collectively learned about Software Bill of Materials (SBOM) s and how .buildinfo files can be seen/used as SBOMs. And, no less importantly, the Reproducible Builds t-shirt design has been updated
Reproducible Builds at European Cyber Week 2022
During the European Cyber Week 2022, a Capture The Flag (CTF) cybersecurity challenge was created by Fr d ric Pierret on the subject of Reproducible Builds. The challenge consisted in a pedagogical sense based on how to make a software release reproducible. To progress through the challenge issues that affect the reproducibility of build (such as build path, timestamps, file ordering, etc.) were to be fixed in steps in order to get the final flag in order to win the challenge.
At the end of the competition, five people succeeded in solving the challenge, all of whom were awarded with a shirt. Fr d ric Pierret intends to create similar challenge in the form of a how to in the Reproducible Builds documentation, but two of the 2022 winners are shown here:
[ ] industry application of R-Bs appears limited, and we seek to understand whether awareness is low or if significant technical and business reasons prevent wider adoption.
This is achieved through interviews with software practitioners and business managers, and touches on both the business and technical reasons supporting the adoption (or not) of Reproducible Builds. The article also begins with an excellent explanation and literature review, and even introduces a new helpful analogy for reproducible builds:
[Users are] able to perform a bitwise comparison of the two binaries to verify that they are identical and that the distributed binary is indeed built from the source code in the way the provider claims. Applied in this manner, R-Bs function as a canary, a mechanism that indicates when something might be wrong, and offer an improvement in security over running unverified binaries on computer systems.
The full paper is available to download on an open access basis.
Elsewhere in academia, Beatriz Michelson Reichert and Rafael R. Obelheiro have published a paper proposing a systematic threat model for a generic software development pipeline identifying possible mitigations for each threat (PDF). Under the Tampering rubric of their paper, various attacks against Continuous Integration (CI) processes:
An attacker may insert a backdoor into a CI or build tool and thus introduce vulnerabilities into the software (resulting in an improper build). To avoid this threat, it is the developer s responsibility to take due care when making use of third-party build tools. Tampered compilers can be mitigated using diversity, as in the diverse double compiling (DDC) technique. Reproducible builds, a recent research topic, can also provide mitigation for this problem. (PDF)
Misc news
A change was proposed for the Go programming language to enable reproducible builds when Link Time Optimisation (LTO) is enabled. As mentioned in the changelog, Morten Linderud s patch fixes two issues when the linker used in conjunction with the -flto option: the first involves solving an issue related to seeded random numbers; and the second involved the binary embedding the current working directory in compressed sections of the LTO object. Both of these issues made the build unreproducible.
Our monthly IRC meeting was held on November 29th 2022. Our next meeting will be on January 31st 2023; we ll skip the meeting in December due to the proximity to Christmas, etc.
Vagrant Cascadian posed an interesting question regarding the difference between test builds vs rebuilds (or verification rebuilds ). As Vagrant poses in their message, they re both useful for slightly different purposes, and it might be good to clarify the distinction [ ].
Debian & other Linux distributions
Over 50 reviews of Debian packages were added this month, another 48 were updated and almost 30 were removed, all of which adds to our knowledge about identified issues. Two new issue types were added as well. [][].
Vagrant Cascadian announced on our mailing list another online sprint to help clear the huge backlog of reproducible builds patches submitted by performing NMUs (Non-Maintainer Uploads). The first such sprint took place on September 22nd, but others were held on October 6th and October 20th. There were two additional sprints that occurred in November, however, which resulted in the following progress:
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 226 and 227 to Debian:
Support both python3-progressbar and python3-progressbar2, two modules providing the progressbar Python module. []
Don t run Python decompiling tests on Python bytecode that file(1) cannot detect yet and Python 3.11 cannot unmarshal. (#1024335)
Don t attempt to attach text-only differences notice if there are no differences to begin with. (#1024171)
Make sure we recommend apksigcopier. []
Tidy generation of os_list. []
Make the code clearer around generating the Debian substvars . []
Use our assert_diff helper in test_lzip.py. []
Drop other copyright notices from lzip.py and test_lzip.py. []
In addition to this, Christopher Baines added lzip support [], and FC Stegerman added an optimisation whereby we don t run apktool if no differences are detected before the signing block [].
A significant number of changes were made to the Reproducible Builds website and documentation this month, including Chris Lamb ensuring the openEuler logo is correctly visible with a white background [], FC Stegerman de-duplicated by email address to avoid listing some contributors twice [], Herv Boutemy added Apache Maven to the list of affiliated projects [] and boyska updated our Contribute page to remark that the Reproducible Builds presence on salsa.debian.org is not just the Git repository but is also for creating issues [][]. In addition to all this, however, Holger Levsen made the following changes:
Add a number of existing publications [][] and update metadata for some existing publications as well [].
Add the Warpforge build tool as a participating project of the summit. []
Clarify in the footer that we welcome patches to the website repository. []
Testing framework
The Reproducible Builds project operates a comprehensive testing framework at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility. In October, the following changes were made by Holger Levsen:
Improve the generation of meta package sets (used in grouping packages for reporting/statistical purposes) to treat Debian bookworm as equivalent to Debian unstable in this specific case []
and to parse the list of packages used in the Debian cloud images [][][].
Temporarily allow Frederic to ssh(1) into our snapshot server as the jenkins user. []
Keep some reproducible jobs Jenkins logs much longer [] (later reverted).
Improve the node health checks to detect failures to update the Debian cloud image package set [][] and to improve prioritisation of some kernel warnings [].
Always echo any IRC output to Jenkins output as well. []
Deal gracefully with problems related to processing the cloud image package set. []
Finally, Roland Clobus continued his work on testing Live Debian images, including adding support for specifying the origin of the Debian installer [] and to warn when the image has unmet dependencies in the package list (e.g. due to a transition) [].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. You can get in touch with us via:
If you ve done anything in the Kubernetes space in recent years, you ve most likely come across the words Service Mesh . It s backed by a set of mature technologies that provides cross-cutting networking, security, infrastructure capabilities to be used by workloads running in Kubernetes in a manner that is transparent to the actual workload. This abstraction enables application developers to not worry about building in otherwise sophisticated capabilities for networking, routing, circuit-breaking and security, and simply rely on the services offered by the service mesh.In this post, I ll be covering Linkerd, which is an alternative to Istio. It has gone through a significant re-write when it transitioned from the JVM to a Go-based Control Plane and a Rust-based Data Plane a few years back and is now a part of the CNCF and is backed by Buoyant. It has proven itself widely for use in production workloads and has a healthy community and release cadence.It achieves this with a side-car container that communicates with a Linkerd control plane that allows central management of policy, telemetry, mutual TLS, traffic routing, shaping, retries, load balancing, circuit-breaking and other cross-cutting concerns before the traffic hits the container. This has made the task of implementing the application services much simpler as it is managed by container orchestrator and service mesh. I covered Istio in a prior post a few years back, and much of the content is still applicable for this post, if you d like to have a look.Here are the broad architectural components of Linkerd:The components are separated into the control plane and the data plane.The control plane components live in its own namespace and consists of a controller that the Linkerd CLI interacts with via the Kubernetes API. The destination service is used for service discovery, TLS identity, policy on access control for inter-service communication and service profile information on routing, retries, timeouts. The identity service acts as the Certificate Authority which responds to Certificate Signing Requests (CSRs) from proxies for initialization and for service-to-service encrypted traffic. The proxy injector is an admission webhook that injects the Linkerd proxy side car and the init container automatically into a pod when the linkerd.io/inject: enabled is available on the namespace or workload.On the data plane side are two components. First, the init container, which is responsible for automatically forwarding incoming and outgoing traffic through the Linkerd proxy via iptables rules. Second, the Linkerd proxy, which is a lightweight micro-proxy written in Rust, is the data plane itself.I will be walking you through the setup of Linkerd (2.12.2 at the time of writing) on a Kubernetes cluster.Let s see what s running on the cluster currently. This assumes you have a cluster running and kubectl is installed and available on the PATH.
On most systems, this should be sufficient to setup the CLI. You may need to restart your terminal to load the updated paths. If you have a non-standard configuration and linkerd is not found after the installation, add the following to your PATH to be able to find the cli:
export PATH=$PATH:~/.linkerd2/bin/
At this point, checking the version would give you the following:
$ linkerd version Client version: stable-2.12.2 Server version: unavailable
Setting up Linkerd Control PlaneBefore installing Linkerd on the cluster, run the following step to check the cluster for pre-requisites:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
pre-kubernetes-setup -------------------- control plane namespace does not already exist can create non-namespaced resources can create ServiceAccounts can create Services can create Deployments can create CronJobs can create ConfigMaps can create Secrets can read Secrets can read extension-apiserver-authentication configmap no clock skew detected
linkerd-version --------------- can determine the latest version cli is up-to-date
Status check results are
All the pre-requisites appear to be good right now, and so installation can proceed.The first step of the installation is to setup the Custom Resource Definitions (CRDs) that Linkerd requires. The linkerd cli only prints the resource YAMLs to standard output and does not create them directly in Kubernetes, so you would need to pipe the output to kubectl apply to create the resources in the cluster that you re working with.
$ linkerd install --crds kubectl apply -f - Rendering Linkerd CRDs... Next, run linkerd install kubectl apply -f - to install the control plane.
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/httproutes.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/meshtlsauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/networkauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serverauthorizations.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/servers.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io created
Next, install the Linkerd control plane components in the same manner, this time without the crds switch:
$ linkerd install kubectl apply -f - namespace/linkerd created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity created serviceaccount/linkerd-identity created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-destination created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-destination created serviceaccount/linkerd-destination created secret/linkerd-sp-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-sp-validator-webhook-config created secret/linkerd-policy-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-policy-validator-webhook-config created clusterrole.rbac.authorization.k8s.io/linkerd-policy created clusterrolebinding.rbac.authorization.k8s.io/linkerd-destination-policy created role.rbac.authorization.k8s.io/linkerd-heartbeat created rolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created serviceaccount/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created serviceaccount/linkerd-proxy-injector created secret/linkerd-proxy-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-proxy-injector-webhook-config created configmap/linkerd-config created secret/linkerd-identity-issuer created configmap/linkerd-identity-trust-roots created service/linkerd-identity created service/linkerd-identity-headless created deployment.apps/linkerd-identity created service/linkerd-dst created service/linkerd-dst-headless created service/linkerd-sp-validator created service/linkerd-policy created service/linkerd-policy-validator created deployment.apps/linkerd-destination created cronjob.batch/linkerd-heartbeat created deployment.apps/linkerd-proxy-injector created service/linkerd-proxy-injector created secret/linkerd-config-overrides created
Kubernetes will start spinning up the data plane components and you should see the following when you list the pods:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
linkerd-existence ----------------- 'linkerd-config' config map exists heartbeat ServiceAccount exist control plane replica sets are ready no unschedulable pods control plane pods are ready cluster networks contains all pods cluster networks contains all services
linkerd-config -------------- control plane Namespace exists control plane ClusterRoles exist control plane ClusterRoleBindings exist control plane ServiceAccounts exist control plane CustomResourceDefinitions exist control plane MutatingWebhookConfigurations exist control plane ValidatingWebhookConfigurations exist proxy-init container runs as root user if docker container runtime is used
linkerd-identity ---------------- certificate config is valid trust anchors are using supported crypto algorithm trust anchors are within their validity period trust anchors are valid for at least 60 days issuer cert is using supported crypto algorithm issuer cert is within its validity period issuer cert is valid for at least 60 days issuer cert is issued by the trust anchor
linkerd-webhooks-and-apisvc-tls ------------------------------- proxy-injector webhook has valid cert proxy-injector cert is valid for at least 60 days sp-validator webhook has valid cert sp-validator cert is valid for at least 60 days policy-validator webhook has valid cert policy-validator cert is valid for at least 60 days
linkerd-version --------------- can determine the latest version cli is up-to-date
control-plane-version --------------------- can retrieve the control plane version control plane is up-to-date control plane and cli versions match
linkerd-control-plane-proxy --------------------------- control plane proxies are healthy control plane proxies are up-to-date control plane proxies and cli versions match
Status check results are
Everything looks good.Setting up the Viz ExtensionAt this point, the required components for the service mesh are setup, but let s also install the viz extension, which provides a good visualization capabilities that will come in handy subsequently. Once again, linkerd uses the same pattern for installing the extension.
$ linkerd viz install kubectl apply -f - namespace/linkerd-viz created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created serviceaccount/metrics-api created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-admin created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-delegator created serviceaccount/tap created rolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-reader created secret/tap-k8s-tls created apiservice.apiregistration.k8s.io/v1alpha1.tap.linkerd.io created role.rbac.authorization.k8s.io/web created rolebinding.rbac.authorization.k8s.io/web created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-admin created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created serviceaccount/web created server.policy.linkerd.io/admin created authorizationpolicy.policy.linkerd.io/admin created networkauthentication.policy.linkerd.io/kubelet created server.policy.linkerd.io/proxy-admin created authorizationpolicy.policy.linkerd.io/proxy-admin created service/metrics-api created deployment.apps/metrics-api created server.policy.linkerd.io/metrics-api created authorizationpolicy.policy.linkerd.io/metrics-api created meshtlsauthentication.policy.linkerd.io/metrics-api-web created configmap/prometheus-config created service/prometheus created deployment.apps/prometheus created service/tap created deployment.apps/tap created server.policy.linkerd.io/tap-api created authorizationpolicy.policy.linkerd.io/tap created clusterrole.rbac.authorization.k8s.io/linkerd-tap-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-tap-injector created serviceaccount/tap-injector created secret/tap-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-tap-injector-webhook-config created service/tap-injector created deployment.apps/tap-injector created server.policy.linkerd.io/tap-injector-webhook created authorizationpolicy.policy.linkerd.io/tap-injector created networkauthentication.policy.linkerd.io/kube-api-server created service/web created deployment.apps/web created serviceprofile.linkerd.io/metrics-api.linkerd-viz.svc.cluster.local created serviceprofile.linkerd.io/prometheus.linkerd-viz.svc.cluster.local created
A few seconds later, you should see the following in your pod list:
The viz components live in the linkerd-viz namespace.You can now checkout the viz dashboard:
$ linkerd viz dashboard Linkerd dashboard available at: http://localhost:50750 Grafana dashboard available at: http://localhost:50750/grafana Opening Linkerd dashboard in the default browser Opening in existing browser session.
The Meshed column indicates the workload that is currently integrated with the Linkerd control plane. As you can see, there are no application deployments right now that are running.Injecting the Linkerd Data Plane componentsThere are two ways to integrate Linkerd to the application containers:1 by manually injecting the Linkerd data plane components 2 by instructing Kubernetes to automatically inject the data plane componentsInject Linkerd data plane manuallyLet s try the first option. Below is a simple nginx-app that I will deploy into the cluster:
Back in the viz dashboard, I do see the workload deployed, but it isn t currently communicating with the Linkerd control plane, and so doesn t show any metrics, and the Meshed count is 0:Looking at the Pod s deployment YAML, I can see that it only includes the nginx container:
Let s directly inject the linkerd data plane into this running container. We do this by retrieving the YAML of the deployment, piping it to linkerd cli to inject the necessary components and then piping to kubectl apply the changed resources.
Back in the viz dashboard, the workload now is integrated into Linkerd control plane.Looking at the updated Pod definition, we see a number of changes that the linkerd has injected that allows it to integrate with the control plane. Let s have a look:
At this point, the necessary components are setup for you to explore Linkerd further. You can also try out the jaeger and multicluster extensions, similar to the process of installing and using the viz extension and try out their capabilities.Inject Linkerd data plane automaticallyIn this approach, we shall we how to instruct Kubernetes to automatically inject the Linkerd data plane to workloads at deployment time.We can achieve this by adding the linkerd.io/inject annotation to the deployment descriptor which causes the proxy injector admission hook to execute and inject linkerd data plane components automatically at the time of deployment.
This annotation can also be specified at the namespace level to affect all the workloads within the namespace. Note that any resources created before the annotation was added to the namespace will require a rollout restart to trigger the injection of the Linkerd components.Uninstalling LinkerdNow that we have walked through the installation and setup process of Linkerd, let s also cover how to remove it from the infrastructure and go back to the state prior to its installation.The first step would be to remove extensions, such as viz.
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: AA66280D4EF0BFCC6BFC2104DA5ECB231C8F04C4
I plan to use the new key for things like encrypted emails, uploads to the Debian archive, and more. Also,
the new key includes an identity with a newer personal email address I plan to use soon: arturo.bg@arturo.bg
The new key has been uploaded to some public keyservers.
If you would like to sign the new key, please follow the steps in the Debian wiki.
If you are curious about what that long code block contains, check this https://cirw.in/gpg-decoder/
For the record, the old key fingerprint is: DD9861AB23DC3333892E07A968E713981D1515F8
Cheers!
Review: What Makes This Book So Great, by Jo Walton
Publisher:
Tor
Copyright:
January 2014
ISBN:
0-7653-3193-4
Format:
Hardcover
Pages:
447
Jo Walton, in addition to being an excellent science fiction and fantasy
writer, is a prodigious reader and frequent participant in on-line SFF
book discussion going back to the Usenet days. This book is a collection
of short essays previously published on Tor.com between July 2008 and February 2011. The unifying theme is that
Walton regularly re-reads her favorite books, and each essay (apart from
some general essays on related topics) is about why this specific book is
one that she re-reads, and (as the title says) what makes it so great.
Searching for the title of one of the essays turns it up on Tor.com still,
so this is one of those collections that you don't have to buy since you
can read its contents on-line for free. That said, it looks like these
essays were from before Tor.com started classifying posts into series, so
it's going to be challenging to track them down in the huge number of
other articles Walton has written for the site. (That said, you can't go
far wrong by reading any of her essays at random.)
I read these essays as they were originally published, so this was also a
re-read for me, but it had been a while. I'm happy to report that they
were just as much fun the second time.
In the introduction and in the final essay of this collection, Walton
draws a distinction between what she's doing, criticism, and reviewing.
As someone else who writes about books (in a far more amateur fashion), I
liked this distinction.
The way I'd characterize it is that criticism is primarily about the work:
taking it apart to see what makes it tick, looking for symbolism and
hidden meanings, and comparing and contrasting other works that are
tackling similar themes. I've often finished a work of criticism and
still had no idea if the author enjoyed reading the work being criticized
or not, since that isn't the point.
Reviewing is assistance to consumers and focuses more on the reader: would
you enjoy this book? Is it enjoyable to read? Does it say something new?
What genre and style is it in, so that you can match that to your tastes?
Talking about books is neither of those things, although it's a bit closer
to reviewing. But the emphasis is on one's personal enjoyment instead of
attempting to review a product for others. When I talk about books with
friends, I talk primarily about what bits I liked, what bits I didn't
like, where the emotional beats were for me, and what interesting things
the book did that surprised me or caught my attention. One can find a
review in there, and sometimes even criticism, but the focus and the
formality is different. (And, to be honest, my reviews are more on the
"talking about the book" side than fully proper reviews.)
These essays are indeed talking about books. They're all re-reads; in
some cases the first re-read, but more frequently the latest of many
re-reads. There are lots of spoilers, which makes for bad reviews (the
target audience of a review hasn't read the book yet) but good fodder for
conversations about books. (The spoilers are mostly marked, but if you're
particularly averse to spoilers, you'll need to read carefully.) Most of
the essays are about a single book, but there are a few on more general
topics, such as Walton's bafflement that anyone would skim a novel.
Since these are re-reads, and the essays collected here are more than a
decade old, the focus is on older books. Some of them are famous: Vinge's
A Fire Upon the Deep and
A Deepness in the Sky, early Le Guin,
Samuel Delaney's SF novels, Salmon Rushdie's Midnight's Children.
Some of them are more obscure. C.J. Cherryh, for example, is a writer who
never seems to get much on-line attention, but who is one of Walton's
favorites.
Most of the essays stand alone or come in small clusters about a writer,
often sprinkled through the book instead of clumped together. (The book
publishes the essays in the same order they originally appeared on
Tor.com.) The two largest groups of essays are re-readings of every book
in Steven Brust's Vlad Taltos universe (including
Brokedown Palace and the
Paarfi books) up to Jhegaala, and every book in Lois McMaster Bujold's Miles
Vorkosigan series up to Diplomatic
Immunity. This is fitting: those are two of the great series of science
fiction, but don't seem to be written about nearly as much as I would
expect.
There are over 130 essays in a 447 page book, so there's a lot of material
here and none of them outlive their welcome. Walton has a comfortable,
approachable style that bubbles with delight and appreciation for books.
I think it's impossible to read this collection without wanting to read
more, and without adding several more books to the ever-teetering to-read
pile.
This is perhaps not the best source of reading recommendations if you
dislike spoilers, although it can be used for that if you read carefully.
But if you love listening to conversations about the genre and talking
about how books bounce off each other, and particularly if you have read
most of these books already or don't mind spoilers, this collection is a
delight. If you're the type of SFF reader who likes reading the reviews
in Locus or is already reading Tor.com, highly recommended.
Rating: 8 out of 10
History
Before I start, the game I was talking about is called Cell To Singularity. Now I haven t gone much in the game as I have shared but think that the Singularity it refers to is the Technological Singularity that people think will happen. Whether that will happen or not is open to debate to one and all. This is going to be a bit long one.
Confession Time :- When I was sharing in the blog post, I had no clue that we actually had sessions on it in this year s Debconf. I just saw the schedule yesterday and then came to know. Then I saw Guido s two talks, one at Debconf as well as one as Froscon. In fact, saw the Froscon talk first, and then the one at Debconf. Both the talks are nearly the same except for a thing here or a thing there.
Now because I was not there so my understanding and knowledge would be disadvantageously asymmetrical to Guido and others who were there and could talk and share more. Having a Debian mobile or Debian on the mobile could also make Debian more popular and connectable to the masses, one of the things that were not pointed out in the Debian India BOF sadly. At the same time, there are some facts that are not on the table and hence not thought about.
Being a B.Com person, I have been following not just the technical but also how the economics work and smartphone penetration in India is pretty low or historically been very low, say around 3-4% while the majority that people use, almost 90-95% of the market uses what are called non-smartphones or dumbphones. Especially during the pandemic and even after that the dumbphones market actually went up while smartphones stagnated and even came down. There is a lot of inventory at most of the dealers that they can t get rid of. From a dealer perspective, it probably makes more sense to buy and sell dumbphones more in number as the turnaround of capital is much faster and easier than for smartphones. I have seen people spend a number of hours and rightly so in order to make their minds up on a smartphone while for a dumbphone, it is a 10-minute thing. Ask around, figure out who is selling at the cheapest, and just buy. Most of these low-end phones are coming from China. In fact, even in the middle and getting even into smartphones, the Chinese are the masters from whom we buy, even as they have occupied Indian territory. In the top five, Samsung comes at number three of four (sharing about Samsung as a fan and having used them.) even though battery times are atrocious, especially with Android 12L. The only hope that most of the smartphone manufacturers have is lowering the sticker prices and hoping that 5G Adoption picks up and that is what they are betting on but that comes with its own share of drawbacks as can be seen.
GNOME, MATE, memory leaks, Payments
FWIW, while I do have GNOME and do use a couple of tools from the GNOME stack, I hate GNOME with a passion. I have been a mate user for almost a decade now and really love the simplicity that mate has vis-a-vis GNOME. And with each release, MATE has only become better. So, it would be nice if we can have MATE on the mobile phone. How adaptive the apps might be on the smaller area, I dunno. It would be interesting to find out if and how people are looking at debugging memory leaks on mobile phones. Although finding memory leaks on any platform is good, finding them and fixing them on a mobile phone is pretty much critical as most phones have fixed & relatively small amounts of memory and it is and can get quickly exhausted.
One of the things that were asked in the Q&A was about payments. The interesting thing is both UK and India are the same or markedly similar in regard as far as contactless payments being concerned. What most Indians have or use is basically UPI which is basically backed by your bank. Unlike in some other countries where you have a selection of wallets and even temporary/permanent virtual accounts whereby you can minimize your risks in case your mobile gets stolen or something, here we don t have that. There are three digital wallets that I know Paytm Not used (have heard it s creepy, but don t really know), Google pay (Unfortunately, this is the one I use, they bought multiple features, and in the last couple of years have really taken the game away from Paytm but also creepy.). The last one is Samsung Pay (haven t really used it as their find my phone app. always crashes, dunno how it is supposed to work.) But I do find that the apps. are vulnerable. Every day there is some or other news of fraud happening. Previously, only States like Bihar and Jharkhand used to be infamous for cybercrime as a hub, but now even States like Andhra Pradesh have joined and surpassed them :(. People have lost lakhs and crores, this is just a few days back. Some more info. on UPI can be found here and GitHub has a few implementation examples that anybody could look at and run away with it.
Balancing on three things
For any new mobile phone to crack the market, it has to balance three things. One, achieve economies of scale. Unless, that is not taken care of or done, however good or bad the product might be, it remains a niche and dies after some time. While Guido shared about Openmoko and N900, one of the more interesting bits from a user perspective at least was the OLPC project. There are many nuances that the short article didn t go through. While I can t say for other countries, at least in India, no education initiative happens without corruption. And perhaps Nicholas s hands were tied while other manufacturers would and could do to achieve their sales targets. In India, it flopped because there was no way for volunteers to buy or get OLPC unless they were part of a school or college. There was some traction in FOSS communities, but that died down once OLPC did the partnership with MS-Windows, and proverbially broke the camel s back. FWIW, I think the idea, the concept, and even the machine were far ahead of their time.
The other two legs are support and Warranty Without going into any details, I can share and tell there were quite a few OLPC type attempts using conventional laptops or using Android and FOSS or others or even using one of the mainstream distributions but the problems have always been polishing, training and support. Guido talked about privacy as a winning feature but fails to take into account that people want to know that their privacy isn t being violated. If a mobile phone answers to Hey Google does it mean it was passively gathering, storing, and sending info to third parties, we just don t know. The mobile phone could be part of the right to repair profile while at the same time it can force us to ask many questions about the way things currently are and going to be. Six months down the line all the flagships of all companies are working on being able to take and share through satellites (Satellite Internet) and perhaps maybe a few non-flagships. Of course, if you are going to use a satellite, then you are going to drain that much more quickly. In all and every event there are always gonna be tradeoffs.
The Debian-mobile mailing list doesn t seem to have many takers. The latest I could find there is written by Paul Wise. I am in a similar boat (Samsung; SM-M526B; Lahaina; arm64-v8a) v12. It is difficult to know which release would work on your machine, make sure that the building from the source is not tainted and pristine and needs a way to backup and restore if you need to. I even tried installing GNURoot Debian and the Xserver alternative they had shared but was unable to use the touch interface on the fakeroot instance . The system talks about a back key but what back key I have no clue.
Precursor Events Debconf 2023
As far as precursor events are concerned before Debconf 23 in India, all the festivals that we have could be used to showcase Debian. In fact, the ongoing Ganesh Chaturthi would have been the perfect way to showcase Debian and apps. according to the audience. Even the festival of Durga Puja, Diwali etc. can be used. When commercial organizations use the same festivals, why can t we? What perhaps we would need to figure out is the funding part as well as getting permissions from Municipal authorities. One of the things for e.g. that we could do is buy either a permanent 24 monitor or a 34 TV and use that to display Debian and apps. The bigger, the better. Something that we could use day to day and also is used for events. This would require significant amounts of energy so we could approach companies, small businesses and individuals both for volunteering as well as helping out with funding.
Somebody asked how we could do online stuff and why it is somewhat boring. What could be done for e.g. instead of 4-5 hrs. of things, break it into manageable 45 minute pieces. 4-5 hrs. is long and is gonna fatigue the best of people. Make it into 45-minute negotiable chunks, and intersphere it with jokes, hacks, anecdotes, and war stories. People do not like or want to be talked down to but rather converse. One of the things that I saw many of the artists do is have shows and limit the audience to 20-24 people on zoom call or whatever videoconferencing system you have and play with them. The passive audience enjoys the play between the standup guy and the crowd he works on, some of them may be known to him personally so he can push that envelope a bit more. The same thing can be applied here. Share the passion, and share why we are doing something. For e.g. you could do smem -t -k less and give a whole talk about how memory is used and freed during a session, how are things different on desktop and ARM as far as memory architecture is concerned (if there is). What is being done on the hardware side, what is on the software side and go on and on. Then share about troubleshooting applications. Valgrind is super slow and makes life hell, is there some better app ? Doesn t matter if you are a front-end or a back-end developer you need to know this and figure out the best way to deal with in your app/program. That would have lot of value. And this is just an e.g. to help trigger more ideas from the community. I am sure others probably have more fun ideas as to what can be done. I am stopping here now otherwise would just go on, till later. Feel free to comment, feedback. Hope it generates some more thinking and excitement on the grey cells.
Among my collection of PC hardware, I have a few rarities whose netboot implementation predates PXE. Since I recently managed to configure dnsmasq as a potent TFTP and PXE server, I figured that I'd try chainloading iPXE via BOOTP options. This required preparing a boot image using antiquated tools:
$ sudo mkelf-linux --param=autoboot --output=/srv/tftp/ipxe.nbi /srv/tftp/ipxe.lkrn
The host succesufully loads the boot image, except that the iPXE blob fails to find the network card:
Since the first week of April 2022 I have (finally!) changed my company car from
a plug-in hybrid to a fully electic car. My new ride, for the next two years, is
a BMW i4 M50 in Aventurine Red metallic.
An ellegant car with very deep and
memorable color, insanely powerful (544 hp/795 Nm), sub-4 second 0-100 km/h, large
84 kWh battery (80 kWh usable), charging up to 210 kW, top speed of 225 km/h
and also very efficient (which came out best in this trip) with WLTP range of 510 km
and EVDB real range of 435 km. The car
also has performance tyres (Hankook Ventus S1 evo3 245/45R18 100Y XL in front and
255/45R18 103Y XL in rear all at recommended 2.5 bar) that have reduced efficiency.
So I wanted to document and describe how was it for me to travel ~2000 km (one way)
with this, electric, car from south of Germany to north of Latvia. I have done
this trip many times before since I live in Germany now and travel back to my
relatives in Latvia 1-2 times per year. This was the first time I made this trip in
an electric car. And as this trip includes both travelling in Germany (where BEV
infrastructure is best in the world) and across Eastern/Northen Europe, I believe
that this can be interesting to a few people out there.
Normally when I travelled this trip with a gasoline/diesel car I would normally drive
for two days with an intermediate stop somewhere around Warsaw with about 12 hours
of travel time in each day. This would normally include a couple bathroom stops in each
day, at least one longer lunch stop and 3-4 refueling stops on top of that. Normally
this would use at least 6 liters of fuel per 100 km on average with total usage of about
270 liters for the whole trip (or about 540 just in fuel costs, nowadays). My
(personal) quirk is that both fuel and recharging of my (business) car inside Germany
is actually paid by my employer, so it is useful
for me to charge up (or fill up) at the last station in Gemany before driving on.
The plan for this trip was made in a similar way as when travelling with a gasoline car:
travelling as fast as possible on German Autobahn network to last chargin stop on the A4
near G rlitz, there charging up as much as reasonable and then travelling to a hotel
in Warsaw, charging there overnight and travelling north towards Ionity chargers in
Lithuania from where reaching the final target in north of Latvia should be possible.
How did this plan meet the reality?
Travelling inside Germany with an electric car was basically perfect. The most efficient
way would involve driving fast and hard with top speed of even 180 km/h (where possible
due to speed limits and traffic). BMW i4 is very efficient at high speeds with consumption
maxing out at 28 kWh/100km when you actually drive at this speed all the time. In real
situation in this trip we saw consumption of 20.8-22.2 kWh/100km in the first legs of the trip.
The more traffic there is, the more speed limits and roadworks, the lower is the average
speed and also the lower the consumption. With this kind of consumption we could comfortably
drive 2 hours as fast as we could and then pick any fast charger along the route and in
26 minutes at a charger (50 kWh charged total) we'd be ready to drive for another 2 hours.
This lines up very well with recommended rest stops for biological reasons (bathroom, water
or coffee, a bit of movement to get blood circulating) and very close to what I had to do
anyway with a gasoline car. With a gasoline car I had to refuel first, then park, then go to
bathroom and so on. With an electric car I can do all of that while the car is charging and
in the end the total time for a stop is very similar. Also not that there was a crazy heat
wave going on and temperature outside was at about 34C minimum the whole day and hitting
40C at one point of the trip, so a lot of power was used for cooling. The car has a heat pump
standard, but it still was working hard to keep us cool in the sun.
The car was able to plan a charging route with all the charging stops required and had all
the good options (like multiple intermediate stops) that many other cars (hi Tesla) and
mobile apps (hi Google and Apple) do not have yet. There are a couple bugs with charging
route and display of current route guidance, those are already fixed and will be delivered
with over the air update with July 2022 update. Another good alterantive is the ABRP (A
Better Route Planner) that was specifically designed for electric car routing along the
best route for charging. Most phone apps (like Google Maps) have no idea about your specific
electric car - it has no idea about the battery capacity, charging curve and is missing key
live data as well - what is the current consumption and remaining energy in the battery. ABRP
is different - it has data and profiles for almost all electric cars and can also be linked to
live vehicle data, either via a OBD dongle or via a new Tronity cloud service. Tronity reads
data from vehicle-specific cloud service, such as MyBMW service, saves it, tracks history and
also re-transmits it to ABRP for live navigation planning. ABRP allows for options and settings
that no car or app offers, for example, saying that you want to stop at a particular place for
an hour or until battery is charged to 90%, or saying that you have specific charging cards and
would only want to stop at chargers that support those. Both the car and the ABRP also support
alternate routes even with multiple intermediate stops. In comparison, route planning by Google
Maps or Apple Maps or Waze or even Tesla does not really come close.
After charging up in the last German fast charger, a more interesting part of the trip started.
In Poland the density of high performance chargers (HPC) is much lower than in Germany. There are
many chargers (west of Warsaw), but vast majority of them are (relatively) slow 50kW chargers.
And that is a difference between putting 50kWh into the car in 23-26 minutes or in 60 minutes. It
does not seem too much, but the key bit here is that for 20 minutes there is easy to find stuff
that should be done anyway, but after that you are done and you are just waiting for the car and
if that takes 4 more minutes or 40 more minutes is a big, perceptual, difference. So using
HPC is much, much preferable. So we put in the Ionity charger near Lodz as our intermediate target
and the car suggested an intermediate stop at a Greenway charger by Katy Wroclawskie. The location
is a bit weird - it has 4 charging stations with 150 kW each. The weird bits are that each station
has two CCS connectors, but only one parking place (and the connectors share power, so if two cars
were to connect, each would get half power). Also from the front of the location one can only see
two stations, the otehr two are semi-hidden around a corner. We actually missed them on the way
to Latvia and one person actually waited for the charger behind us for about 10 minutes. We only
discovered the other two stations on the way back. With slower speeds in Poland the consumption
goes down to 18 kWh/100km which translates to now up to 3 hours driving between stops.
At the end of the first day we drove istarting from Ulm from 9:30 in the morning until about 23:00 in the evening with
total distance of about 1100 km, 5 charging stops, starting with 92% battery, charging for
26 min (50 kWh), 33 min (57 kWh + lunch), 17 min (23 kWh), 12 min (17 kWh) and 13 min (37 kW).
In the last two chargers you can see the difference between a good and fast 150 kW charger at high
battery charge level and a really fast Ionity charger at low battery charge level, which makes
charging faster still.
Arriving to hotel with 23% of battery. Overnight the car charged from a Porsche Destination
Charger to 87% (57 kWh). That was a bit less than I would expect from a full power 11kW charger,
but good enough. Hotels should really install 11kW Type2 chargers for their guests, it is a really
significant bonus that drives more clients to you.
The road between Warsaw and Kaunas is the most difficult part of the trip for both driving itself
and also for charging. For driving the problem is that there will be a new highway going from
Warsaw to Lithuanian border, but it is actually not fully ready yet. So parts of the way one drives
on the new, great and wide highway and parts of the way one drives on temporary roads or on old
single lane undivided roads. And the most annoying part is navigating between parts as signs are
not always clear and the maps are either too old or too new. Some maps do not have the new roads and
others have on the roads that have not been actually build or opened to traffic yet. It's really easy
to loose ones way and take a significant detour. As far as charging goes, basically there is only
the slow 50 kW chargers between Warsaw and Kaunas (for now). We chose to charge on the last charger
in Poland, by Suwalki Kaufland. That was not a good idea - there is only one 50 kW CCS and many people
decide the same, so there can be a wait. We had to wait 17 minutes before we could charge for
30 more minutes just to get 18 kWh into the battery. Not the best use of time. On the way back we chose
a different charger in Lomza where would have a relaxed dinner while the car was charging. That
was far more relaxing and a better use of time.
We also tried charging at an Orlen charger that was not recommended by our car and we found out why.
Unlike all other chargers during our entire trip, this charger did not accept our universal BMW Charging
RFID card. Instead it demanded that we download their own Orlen app and register there. The app is only
available in some countries (and not in others) and on iPhone it is only available in Polish. That is a
bad exception to the rule and a bad example. This is also how most charging works in USA. Here in Europe
that is not normal. The normal is to use a charging card - either provided from the car maker or from
another supplier (like PlugSufring or Maingau Energy). The providers then make roaming arrangements with
all the charging networks, so the cards just work everywhere. In the end the user gets the prices and the
bills from their card provider as a single monthly bill. This also saves all any credit card charges for
the user. Having a clear, separate RFID card also means that one can easily choose how to pay for each
charging session. For example, I have a corporate RFID card that my company pays for (for charging in
Germany) and a private BMW Charging card that I am paying myself for (for charging abroad). Having the
car itself authenticate direct with the charger (like Tesla does) removes the option to choose how to pay.
Having each charge network have to use their own app or token bring too much chaos and takes too much setup.
The optimum is having one card that works everywhere and having the option to have additional card
or cards for specific purposes.
Reaching Ionity chargers in Lithuania is again a breath of fresh air - 20-24 minutes to charge 50 kWh is
as expected. One can charge on the first Ionity just enough to reach the next one and then on the second
charger one can charge up enough to either reach the Ionity charger in Adazi or the final target in Latvia.
There is a huge number of CSDD (Road Traffic and Safety Directorate) managed chargers all over Latvia,
but they are 50 kW chargers. Good enough for local travel, but not great for long distance trips. BMW i4
charges at over 50 kW on a HPC even at over 90% battery state of charge (SoC). This means that it is always
faster to charge up in a HPC than in a 50 kW charger, if that is at all possible. We also tested the CSDD
chargers - they worked without any issues. One could pay with the BMW Charging RFID card, one could use
the CSDD e-mobi app or token and one could also use Mobilly - an app that you can use in Latvia for
everything from parking to public transport tickets or museums or car washes.
We managed to reach our final destination near Aluksne with 17% range remaining after just 3 charging stops:
17+30 min (18 kWh), 24 min (48 kWh), 28 min (36 kWh). Last stop we charged to 90% which took a few extra
minutes that would have been optimal.
For travel around in Latvia we were charging at our target farmhouse from a normal 3 kW Schuko EU socket.
That is very slow. We charged for 33 hours and went from 17% to 94%, so not really full. That was perfectly
fine for our purposes. We easily reached Riga, drove to the sea and then back to Aluksne with 8% still
in reserve and started charging again for the next trip. If it were required to drive around more and charge
faster, we could have used the normal 3-phase 440V connection in the farmhouse to have a red CEE 16A plug
installed (same as people use for welders). BMW i4 comes standard with a new BMW Flexible Fast Charger
that has changable socket adapters. It comes by default with a Schucko connector in Europe, but for 90
one can buy an adapter for blue CEE plug (3.7 kW) or red CEE 16A or 32A plugs (11 kW). Some public charging
stations in France actually use the blue CEE plugs instead of more common Type2 electric car charging stations.
The CEE plugs are also common in camping parking places.
On the way back the long distance BEV travel was already well understood and did not cause us any problem. From
our destination we could easily reach the first Ionity in Lithuania, on the Panevezhis bypass road where
in just 8 minutes we got 19 kWh and were ready to drive on to Kaunas, there a longer 32 minute stop before
the charging desert of Suwalki Gap that gave us 52 kWh to 90%. That brought us to a shopping mall in Lomzha
where we had some food and charged up 39 kWh in lazy 50 minutes. That was enough to bring us to our return hotel
for the night - Hotel 500W in Strykow by Lodz that has a 50kW charger on site, while we were having late
dinner and preparing for sleep, the car easily recharged to full (71 kWh in 95 minutes), so I just moved
it from charger to a parking spot just before going to sleep. Really easy and well flowing day.
Second day back went even better as we just needed an 18 minute stop at the same Katy Wroclawskie charger
as before to get 22 kWh and that was enough to get back to Germany. After that we were again flying on the
Autobahn and charging as needed, 15 min (31 kWh), 23 min (48 kWh) and 31 min (54 kWh + food). We started the
day on about 9:40 and were home at 21:40 after driving just over 1000 km on that day. So less than 12 hours
for 1000 km travelled, including all charging, bio stops, food and some traffic jams as well. Not bad.
Now let's take a look at all the apps and data connections that a technically minded customer can have
for their car. Architecturally the car is a network of computers by itself, but it is very secured and
normally people do not have any direct access. However, once you log in into the car with your BMW account
the car gets your profile info and preferences (seat settings, navigation favorites, ...) and the car then
also can start sending information to the BMW backend about its status. This information is then available
to the user over multiple different channels. There is no separate channel for each of those data flow.
The data only goes once to the backend and then all other communication of apps happens with the backend.
First of all the MyBMW app.
This is the go-to for everything about the car - seeing its current status and location (when not driving),
sending commands to the car (lock, unlock, flash lights, pre-condition, ...) and also monitor and control
charging processes. You can also plan a route or destination in the app in advance and then just send it over
to the car so it already knows where to drive to when you get to the car. This can also integrate with calendar
entries, if you have locations for appointments, for example. This also shows full charging history and
allows a very easy export of that data, here I exported all charging sessions from June and then
trimmed it back to only sessions relevant to the trip and cut off some design elements to have the data more
visible.
So one can very easily see when and where we were charging, how much power we got at each spot and
(if you set prices for locations) can even show costs.
I've already mentioned the Tronity service and its ABRP integration, but it also saves the information that
it gets from the car and gathers that data over time. It has nice aspects, like showing the driven routes
on a map, having ways to do business trip accounting and having good calendar view. Sadly it does not correctly
capture the data for charging sessions (the amounts are incorrect).
Update: after talking to Tronity support, it looks like the bug was in the incorrect value for the usable
battery capacity for my car. They will look into getting th eright values there by default, but as a workaround
one can edit their car in their system (after at least one charging session) and directly set the expected
battery capacity (usable) in the car properties on the Tronity web portal settings.
One other fun way to see data from your BMW is using the BMW integration in Home Assistant.
This brings the car as a device in your own smart home. You can read all the variables from the car current status
(and Home Asisstant makes cute historical charts) and you can even see
interesting trends, for example for remaining range shows much
higher value in Latvia as its prediction is adapted to Latvian road speeds and during the trip it adapts to Polish
and then to German road speeds and thus to higher consumption and thus lower maximum predicted remaining range.
Having the car attached to the Home Assistant also allows you to attach the car to automations, both as data and event
source (like detecting when car enters the "Home" zone) and also as target, so you could flash car lights or even
unlock or lock it when certain conditions are met.
So, what in the end was the most important thing - cost of the trip? In total we charged up 863 kWh, so that would
normally cost one about 290 , which is close to half what this trip would have costed with a gasoline car. Out of
that 279 kWh in Germany (paid by my employer) and 154 kWh in the farmhouse (paid by our wonderful relatives :D) so
in the end the charging that I actually need to pay adds up to 430 kWh or about 150 . Typically, it took about 400
in fuel that I had to pay to get to Latvia and back. The difference is really nice!
In the end I believe that there are three different ways of charging:
incidental charging - this is wast majority of charging in the normal day-to-day life. The car gets charged when
and where it is convinient to do so along the way. If we go to a movie or a shop and there is a chance to leave
the car at a charger, then it can charge up. Works really well, does not take extra time for charging from us.
fast charging - charging up at a HPC during optimal charging conditions - from relatively low level to no more
than 70-80% while you are still doing all the normal things one would do in a quick stop in a long travel
process: bio things, cleaning the windscreen, getting a coffee or a snack.
necessary charging - charging from a whatever charger is available just enough to be able to reach the next
destination or the next fast charger.
The last category is the only one that is really annoying and should be avoided at all costs. Even by shifting
your plans so that you find something else useful to do while necessary charging is happening and thus, at least
partially, shifting it over to incidental charging category. Then you are no longer just waiting for the car,
you are doing something else and the car magically is charged up again.
And when one does that, then travelling with an electric car becomes no more annoying than travelling with
a gasoline car. Having more breaks in a trip is a good thing and makes the trips actually easier and less
stressfull - I was more relaxed during and after this trip than during previous trips. Having the car air
conditioning always be on, even when stopped, was a godsend in the insane heat wave of 30C-38C that we were
driving trough.
Final stats: 4425 km driven in the trip. Average consumption: 18.7 kWh/100km. Time driving: 2 days and 3 hours.
Car regened 152 kWh. Charging stations recharged 863 kWh.
Questions? You can use this i4talk forum thread or this Twitter thread to ask them to me.
The Freedom Phone advertises itself as a "Free speech and privacy first focused phone". As documented on the features page, it runs ClearOS, an Android-based OS produced by Clear United (or maybe one of the bewildering array of associated companies, we'll come back to that later). It's advertised as including Signal, but what's shipped is not the version available from the Signal website or any official app store - instead it's this fork called "ClearSignal".
The first thing to note about ClearSignal is that the privacy policy link from that page 404s, which is not a great start. The second thing is that it has a version number of 5.8.14, which is strange because upstream went from 5.8.10 to 5.9.0. The third is that, despite Signal being GPL 3, there's no source code available. So, I grabbed jadx and started looking for differences between ClearSignal and the upstream 5.8.10 release. The results were, uh, surprising.
First up is that they seem to have integrated ACRA, a crash reporting framework. This feels a little odd - in the absence of a privacy policy, it's unclear what information this gathers or how it'll be stored. Having a piece of privacy software automatically uploading information about what you were doing in the event of a crash with no notification other than a toast that appears saying "Crash Report" feels a little dubious.
Next is that Signal (for fairly obvious reasons) warns you if your version is out of date and eventually refuses to work unless you upgrade. ClearSignal has dealt with this problem by, uh, simply removing that code. The MacOS version of the desktop app they provide for download seems to be derived from a release from last September, which for an Electron-based app feels like a pretty terrible idea. Weirdly, for Windows they link to an official binary release from February 2021, and for Linux they tell you how to use the upstream repo properly. I have no idea what's going on here.
They've also added support for network backups of your Signal data. This involves the backups being pushed to an S3 bucket using credentials that are statically available in the app. It's ok, though, each upload has some sort of nominally unique identifier associated with it, so it's not trivial to just download other people's backups. But, uh, where does this identifier come from? It turns out that Clear Center, another of the Clear family of companies, employs a bunch of people to work on a ClearID[1], some sort of decentralised something or other that seems to be based on KERI. There's an overview slide deck here which didn't really answer any of my questions and as far as I can tell this is entirely lacking any sort of peer review, but hey it's only the one thing that stops anyone on the internet being able to grab your Signal backups so how important can it be.
The final thing, though? They've extended Signal's invitation support to encourage users to get others to sign up for Clear United. There's an exposed API endpoint called "get_user_email_by_mobile_number" which does exactly what you'd expect - if you give it a registered phone number, it gives you back the associated email address. This requires no authentication. But it gets better! The API to generate a referral link to send to others sends the name and phone number of everyone in your phone's contact list. There does not appear to be any indication that this is going to happen.
So, from a privacy perspective, going to go with things being some distance from ideal. But what's going on with all these Clear companies anyway? They all seem to be related to Michael Proper, who founded the Clear Foundation in 2009. They are, perhaps unsurprisingly, heavily invested in blockchain stuff, while Clear United also appears to be some sort of multi-level marketing scheme which has a membership agreement that includes the somewhat astonishing claim that:
Specifically, the initial focus of the Association will provide members with supplements and technologies for:
9a. Frequency Evaluation, Scans, Reports;
9b. Remote Frequency Health Tuning through Quantum Entanglement;
9c. General and Customized Frequency Optimizations;
- there's more discussion of this and other weirdness here. Clear Center, meanwhile, has a Chief Physics Officer? I have a lot of questions.
Anyway. We have a company that seems to be combining blockchain and MLM, has some opinions about Quantum Entanglement, bases the security of its platform on a set of novel cryptographic primitives that seem to have had no external review, has implemented an API that just hands out personal information without any authentication and an app that appears more than happy to upload all your contact details without telling you first, has failed to update this app to keep up with upstream security updates, and is violating the upstream license. If this is their idea of "privacy first", I really hate to think what their code looks like when privacy comes further down the list.
Previously I setup a CC2531 as a Zigbee coordinator for my home automation. This has turned out to be a good move, with the 4 gang wireless switch being particularly useful. However the range of the CC2531 is fairly poor; it has a simple PCB antenna. It s also a very basic device. I set about trying to improve the range and scalability and settled upon a CC2538 + CC2592 device, which feature an MMCX antenna connector. This device also has the advantage that it s ARM based, which I m hopeful means I might be able to build some firmware myself using a standard GCC toolchain.
For now I fetched the JetHome firmware from https://github.com/jethome-ru/zigbee-firmware/tree/master/ti/coordinator/cc2538_cc2592 (JH_2538_2592_ZNP_UART_20211222.hex) - while it s possible to do USB directly with the CC2538 my board doesn t have those bits so going the external USB UART route is easier.
The device had some existing firmware on it, so I needed to erase this to force a drop into the boot loader. That means soldering up the JTAG pins and hooking it up to my Bus Pirate for OpenOCD goodness.
OpenOCD config
source [find interface/buspirate.cfg]
buspirate_port /dev/ttyUSB1
buspirate_mode normal
buspirate_vreg 1
buspirate_pullup 0
transport select jtag
source [find target/cc2538.cfg]
Steps to erase
$ telnet localhost 4444
Trying ::1...
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Open On-Chip Debugger
> mww 0x400D300C 0x7F800
> mww 0x400D3008 0x0205
> shutdown
shutdown command invoked
Connection closed by foreign host.
At that point I can switch to the UART connection (on PA0 + PA1) and flash using cc2538-bsl:
$ git clone https://github.com/JelmerT/cc2538-bsl.git
$ cc2538-bsl/cc2538-bsl.py -p /dev/ttyUSB1 -e -w -v ~/JH_2538_2592_ZNP_UART_20211222.hex
Opening port /dev/ttyUSB1, baud 500000
Reading data from /home/noodles/JH_2538_2592_ZNP_UART_20211222.hex
Firmware file: Intel Hex
Connecting to target...
CC2538 PG2.0: 512KB Flash, 32KB SRAM, CCFG at 0x0027FFD4
Primary IEEE Address: 00:12:4B:00:22:22:22:22
Performing mass erase
Erasing 524288 bytes starting at address 0x00200000
Erase done
Writing 524256 bytes starting at address 0x00200000
Write 232 bytes at 0x0027FEF88
Write done
Verifying by comparing CRC32 calculations.
Verified (match: 0x74f2b0a1)
I then wanted to migrate from the old device to the new without having to repair everything. So I shut down Home Assistant and backed up the CC2531 network information using zigpy-znp (which is already installed for Home Assistant):
I copied the backup to cc2538-network.json and modified the coordinator_ieee to be the new device s MAC address (rather than end up with 2 devices claiming the same MAC if/when I reuse the CC2531) and did:
The old CC2531 needed unplugged first, otherwise I got an RuntimeError: Network formation refused, RF environment is likely too noisy. Temporarily unscrew the antenna or shield the coordinator with metal until a network is formed. error.
After that I updated my udev rules to map the CC2538 to /dev/zigbee and restarted Home Assistant. To my surprise it came up and detected the existing devices without any extra effort on my part. However that resulted in 2 coordinators being shown in the visualisation, with the old one turning up as unk_manufacturer. Fixing that involved editing /etc/homeassistant/.storage/core.device_registry and removing the entry which had the old MAC address, removing the device entry in /etc/homeassistant/.storage/zha.storage for the old MAC and then finally firing up sqlite to modify the Zigbee database:
$ sqlite3 /etc/homeassistant/zigbee.db
SQLite version 3.34.1 2021-01-20 14:10:07
Enter ".help" for usage hints.
sqlite> DELETE FROM devices_v6 WHERE ieee = '00:12:4b:00:11:11:11:11';
sqlite> DELETE FROM endpoints_v6 WHERE ieee = '00:12:4b:00:11:11:11:11';
sqlite> DELETE FROM in_clusters_v6 WHERE ieee = '00:12:4b:00:11:11:11:11';
sqlite> DELETE FROM neighbors_v6 WHERE ieee = '00:12:4b:00:11:11:11:11' OR device_ieee = '00:12:4b:00:11:11:11:11';
sqlite> DELETE FROM node_descriptors_v6 WHERE ieee = '00:12:4b:00:11:11:11:11';
sqlite> DELETE FROM out_clusters_v6 WHERE ieee = '00:12:4b:00:11:11:11:11';
sqlite> .quit
So far it all seems a bit happier than with the CC2531; I ve been able to pair a light bulb that was previously detected but would not integrate, which suggests the range is improved.
(This post another in the set of things I should write down so I can just grep my own website when I forget what I did to do foo .)
My syncmaildir (SMD) setup failed
me one too many times
(previously,
previously). In an attempt to migrate
to an alternative mail synchronization tool, I looked into using my
IMAP server again, and found out my mail spool was in a pretty bad
shape. I'm comparing mbsync and offlineimap in the next
post but this post talks about how
I recovered the mail spool so that tools like those could correctly
synchronise the mail spool again.
The latest crash
On Monday, SMD just started failing with this error:
nov 15 16:12:19 angela systemd[2305]: Starting pull emails with syncmaildir...
nov 15 16:12:22 angela systemd[2305]: smd-pull.service: Succeeded.
nov 15 16:12:22 angela systemd[2305]: Finished pull emails with syncmaildir.
nov 15 16:14:08 angela systemd[2305]: Starting pull emails with syncmaildir...
nov 15 16:14:11 angela systemd[2305]: smd-pull.service: Main process exited, code=exited, status=1/FAILURE
nov 15 16:14:11 angela systemd[2305]: smd-pull.service: Failed with result 'exit-code'.
nov 15 16:14:11 angela systemd[2305]: Failed to start pull emails with syncmaildir.
nov 15 16:16:14 angela systemd[2305]: Starting pull emails with syncmaildir...
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: Network error.
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: Unable to get any data from the other endpoint.
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: This problem may be transient, please retry.
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: Hint: did you correctly setup the SERVERNAME variable
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: on your client? Did you add an entry for it in your ssh
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: configuration file?
nov 15 16:16:17 angela smd-pull[27178]: smd-client: ERROR: Network error
nov 15 16:16:17 angela smd-pull[27188]: register: smd-client@localhost: TAGS: error::context(handshake) probable-cause(network) human-intervention(avoidable) suggested-actions(retry)
nov 15 16:16:17 angela systemd[2305]: smd-pull.service: Main process exited, code=exited, status=1/FAILURE
nov 15 16:16:17 angela systemd[2305]: smd-pull.service: Failed with result 'exit-code'.
nov 15 16:16:17 angela systemd[2305]: Failed to start pull emails with syncmaildir.
What is frustrating is that there's actually no network error
here. Running the command by hand I did see a different message, but
now I have lost it in my backlog. It had something to do with a
filename being too long, and I gave up debugging after a while. This
happened suddenly too, which added to the confusion.
In a fit of rage I started this blog post and experimenting with
alternatives, which led me down a lot of rabbit holes.
Reviewing my previous mail crash
documentation, it seems most
solutions involve talking to an IMAP server, so I figured I would just
do that. Wanting to try something new, i gave isync (AKA
mbsync) a try. Oh dear, I did not expect how much trouble just
talking to my IMAP server would be, which wasn't not isync's fault,
for what that's worth. It was the primary tool I used to debug things,
and served me well in that regard.
Mailbox corruption
The first thing I found out is that certain messages in the IMAP spool
were corrupted. mbsync would stop on a FETCH command and Dovecot
would give me those errors on the server side.
"wrong W value"
nov 16 15:31:27 marcos dovecot[3621800]: imap(anarcat)<3630489><wAmSzO3QZtfAqAB1>: Error: Mailbox junk: Maildir filename has wrong W value, renamed the file from /home/anarcat/Maildir/.junk/cur/1454623938.M101164P22216.marcos,S=2495,W=2578:2,S to /home/anarcat/Maildir/.junk/cur/1454623938.M101164P22216.marcos,S=2495:2,S
nov 16 15:31:27 marcos dovecot[3621800]: imap(anarcat)<3630489><wAmSzO3QZtfAqAB1>: Error: Mailbox junk: Deleting corrupted cache record uid=1582: UID 1582: Broken virtual size in mailbox junk: read(/home/anarcat/Maildir/.junk/cur/1454623938.M101164P22216.marcos,S=2495,W=2578:2,S): FETCH BODY[] got too little data: 2540 vs 2578
At least this first error was automatically healed by Dovecot (by
renaming the file without the W= flag). The problem is that the
FETCH command fails and mbsync exits noisily. So you need to
constantly restart mbsync with a silly command like:
while ! mbsync -a; do sleep 1; done
"cached message size larger than expected"
nov 16 13:53:08 marcos dovecot[3520770]: imap(anarcat)<3594402><M5JHb+zQ3NLAqAB1>: Error: Mailbox Sent: UID=19288: read(/home/anarcat/Maildir/.Sent/cur/1224790447.M898726P9811V000000000000FE06I00794FB1_0.marvin,S=2588:2,S) failed: Cached message size larger than expected (2588 > 2482, box=Sent, UID=19288) (read reason=mail stream)
nov 16 13:53:08 marcos dovecot[3520770]: imap(anarcat)<3594402><M5JHb+zQ3NLAqAB1>: Error: Mailbox Sent: Deleting corrupted cache record uid=19288: UID 19288: Broken physical size in mailbox Sent: read(/home/anarcat/Maildir/.Sent/cur/1224790447.M898726P9811V000000000000FE06I00794FB1_0.marvin,S=2588:2,S) failed: Cached message size larger than expected (2588 > 2482, box=Sent, UID=19288)
nov 16 13:53:08 marcos dovecot[3520770]: imap(anarcat)<3594402><M5JHb+zQ3NLAqAB1>: Error: Mailbox Sent: UID=19288: read(/home/anarcat/Maildir/.Sent/cur/1224790447.M898726P9811V000000000000FE06I00794FB1_0.marvin,S=2588:2,S) failed: Cached message size larger than expected (2588 > 2482, box=Sent, UID=19288) (read reason=)
nov 16 13:53:08 marcos dovecot[3520770]: imap-login: Panic: epoll_ctl(del, 7) failed: Bad file descriptor
This second problem is much harder to fix, because dovecot does not
recover automatically. This is Dovecot complaining that the cached
size (the S= field, but also present in Dovecot's metadata files)
doesn't match the file size.
I wonder if at least some of those messages were corrupted in the
OfflineIMAP to syncmaildir migration
because part of that procedure is to run the strip_header script
to remove content from the emails. That could easily have broken
things since the files do not also get renamed.
Workaround
So I read a lot of the Dovecot documentation on the maildir
format, and wrote an extensive fix script for those two
errors. The script worked and mbsync was able to sync the entire mail
spool.
And no, rebuilding the index files didn't work. Also tried
doveadm force-resync -u anarcat which didn't do anything.
In the end I also had to do this, because the wrong cache values were
also stored elsewhere.
service dovecot stop ; find -name 'dovecot*' -delete; service dovecot start
This would have totally broken any existing clients, but thankfully
I'm starting from scratch (except maybe webmail, but I'm hoping it
will self-heal as well, assuming it only has a cache and not a full
replica of the mail spool).
Incoherence between Maildir and IMAP
Unfortunately, the first mbsync was incomplete as it was missing about
15,000 mails:
anarcat@angela:~(main)$ find Maildir -type f -type f -a \! -name '.*' wc -l
384836
anarcat@angela:~(main)$ find Maildir-mbsync/ -type f -a \! -name '.*' wc -l
369221
As it turns out, mbsync was not at fault here either: this was yet
more mail spool corruption.
It's actually 26 folders (out of 205) with inconsistent sizes, which can
be found with:
for folder in * .[^.]* ; do
printf "%s\t%d\n" $folder $(find "$folder" -type f -a \! -name '.*' wc -l );
done
The special \! -name '.*' bit is to ignore the mbsync metadata,
which creates .uidvalidity and .mbsyncstate in every folder. That
ignores about 200 files but since they are spread around all folders,
which was making it impossible to review where the problem was.
Here is what the diff looks like:
Misfiled messages
It's a bit all over the place, but we can already notice some huge
differences between mailboxes, for example in the Archives
folders. As it turns out, at least 12,000 of those missing mails were
actually misfiled: instead of being in the
Maildir/.Archives.2012/cur/ folder, they were directly in
Maildir/.Archives.2012/. This is something that doesn't matter for
SMD (and possibly for notmuch? it does matter, notmuch suddenly
found 12,000 new mails) but that definitely matters to Dovecot and
therefore mbsync...
After moving those files around, we still have 4,000 message missing:
anarcat@angela:~(main)$ find Maildir-mbsync/ -type f -a \! -name '.*' wc -l
381196
anarcat@angela:~(main)$ find Maildir/ -type f -a \! -name '.*' wc -l
385053
The problem is that those 4,000 missing mails are harder to
track. Take, for example, .Archives.2011, which has a single message
missing, out of 3,582. And the files are not identical: the checksums
don't match after going through the IMAP transport, so we can't use a
tool like hashdeep to compare the trees and find why any single
file is missing.
"register" folder
One big chunk of the 4,000, however, is a special folder called
register in my spool, which I am syncing separately (see Securing
registration email for details on that setup). That actually
covers 3,700 of those messages, so I actually have a more modest 300
messages to figure out, after (easily!) configuring mbsync to sync
that folder separately:
@@ -30,9 +33,29 @@ Slave :anarcat-local:
# Exclude everything under the internal [Gmail] folder, except the interesting folders
#Patterns * ![Gmail]* "[Gmail]/Sent Mail" "[Gmail]/Starred" "[Gmail]/All Mail"
# Or include everything
-Patterns *
+#Patterns *
+Patterns * !register !.register
# Automatically create missing mailboxes, both locally and on the server
#Create Both
Create slave
# Sync the movement of messages between folders and deletions, add after making sure the sync works
#Expunge Both
+
+IMAPAccount anarcat-register
+Host imap.anarc.at
+User register
+PassCmd "pass imap.anarc.at-register"
+SSLType IMAPS
+CertificateFile /etc/ssl/certs/ca-certificates.crt
+
+IMAPStore anarcat-register-remote
+Account anarcat-register
+
+MaildirStore anarcat-register-local
+SubFolders Maildir++
+Inbox ~/Maildir-mbsync/.register/
+
+Channel anarcat-register
+Master :anarcat-register-remote:
+Slave :anarcat-register-local:
+Create slave
"tmp" folders and empty messages
After syncing the "register" messages, I end up with the measly
little 160 emails out of sync:
anarcat@angela:~(main)$ find Maildir-mbsync/ -type f -a \! -name '.*' wc -l
384900
anarcat@angela:~(main)$ find Maildir/ -type f -a \! -name '.*' wc -l
385059
Argh. After more digging, I have found 131 mails in the tmp/
directories of the client's mail spool. Mysterious! On the server
side, it's even more files, and not the same ones. Possible that
those were mails that were left there during a failed delivery of some
sort, during a power failure or some sort of crash? Who knows. It
could be another race condition in SMD if it runs while mail is being
delivered in tmp/...
The first thing to do with those is to cleanup a bunch of empty files
(21 on angela):
find .[^.]*/tmp -type f -empty -delete
As it turns out, they are all duplicates, in the sense that
notmuch can easily find a copy of files with the same message ID in
its database. In other words, this hairy command returns nothing
find .[^.]*/tmp -type f while read path; do
msgid=$(grep -m 1 -i ^message-id "$path" sed 's/Message-ID: //i;s/[<>]//g');
if notmuch count --exclude=false "id:$msgid" grep -q 0; then
echo "$path <$msgid> not in notmuch" ;
fi;
done
... which is good. Or, to put it another way, this is safe:
find .[^.]*/tmp -type f -delete
Poof! 314 mails cleaned on the server side. Interestingly, SMD doesn't
pick up on those changes at all and still sees files in tmp/
directories on the client side, so we need to operate the same twisted
logic there.
notmuch to the rescue again
After cleaning that on the client, we get:
anarcat@angela:~(main)$ find Maildir/ -type f -a \! -name '.*' wc -l
384928
anarcat@angela:~(main)$ find Maildir-mbsync/ -type f -a \! -name '.*' wc -l
384901
Ha! 27 mails difference. Those are the really sticky, unclear ones. I
was hoping a full sync might clear that up, but after deleting the
entire directory and starting from scratch, I end up with:
anarcat@angela:~(main)$ find Maildir -type f -type f -a \! -name '.*' wc -l
385034
anarcat@angela:~(main)$ find Maildir-mbsync -type f -type f -a \! -name '.*' wc -l
384993
That is: even more messages missing (now 37). Sigh.
Thankfully, this is something notmuch can help with:
it can index all files by Message-ID (which I learned is
case-insensitive, yay) and tell us which messages don't make it
through.
Considering the corruption I found in the mail spool, I wouldn't be
the least surprised those messages are just skipped by the IMAP
server. Unfortunately, there's nothing on the Dovecot server logs that
would explain the discrepancy.
Here again, notmuch comes to the rescue. We can list all message IDs
to figure out that discrepancy:
That's 29 messages. Oddly, it doesn't exactly match the find output:
anarcat@angela:~(main)$ find Maildir-mbsync -type f -type f -a \! -name '.*' wc -l
385204
anarcat@angela:~(main)$ find Maildir -type f -type f -a \! -name '.*' wc -l
385241
That is 10 more messages. Ugh. But actually, I know what those are:
more misfiled messages (in a .folder/draft/ directory, bizarrely, so
the totals actually match.
In the notmuch output, there's a lot of stuff like this:
Those are messages without a valid Message-ID. Notmuch (presumably)
constructs one based on the file's checksum. Because the files differ
between the IMAP server and the local mail spool (which is
unfortunate, but possibly inevitable), those do not match. There are
exactly the same number of those on both sides, so I'll go ahead and
assume those are all accounted for.
What remains is:
ie. 21 missing from mbsync, and, surprisingly, 2 missing from the
original mail spool.
Further inspection also showed they were all messages with some sort
of "corruption": no body and only headers. I am not sure that is a
legal email format in the first place. Since they were mostly spam or
administrative emails ("You have been unsubscribed from mailing
list..."), it seems fairly harmless to ignore those.
Conclusion
As we'll see in the next article,
SMD has stellar performance. But that comes at a huge cost: it
accesses the mail storage directly. This can (and has) created
significant problems on the mail server. It's unclear exactly why
those things happen, but Dovecot expects a particular storage format
on its file, and it seems unwise to bypass that.
In the future, I'll try to remember to avoid that, especially since
mechanisms like SMD require special server access (SSH) which, in the
long term, I am not sure I want to maintain or expect.
In other words, just talking with an IMAP server opens up a lot more
possibilities of hosting than setting up a custom synchronisation
protocol over SSH. It's also safer and more reliable, as we have
seen. Thankfully, I've been able to recover from all the errors I
could find, but it could have gone differently and it would have been
possible for SMD to permanently corrupt significant part of my mail
archives.
In the end, however, the last drop was just another weird bug which,
ironically, SMD mysteriously recovered from on its own while I was
writing this documentation and migrating away from it.
In any case, I recommend SMD users start looking for alternatives. The
project has been archived upstream, and the Debian package has
been orphaned. I have seen significant mail box corruption,
including entire mail spool destruction, mostly due to incorrect
locking code. I have filed a release-critical bug in Debian
to make sure it doesn't ship with Debian bookworm.
Alternatives like mbsync provide fast and reliable transport,
including over SSH. See the next
article for further discussion of
the alternatives.
My home automation setup has been fairly static recently; it does what we need and generally works fine. One area I think could be better is controlling it; we have access Home Assistant on our phones, and the Alexa downstairs can control things, but there are no smart assistants upstairs and sometimes it would be nice to just push a button to turn on the light rather than having to get my phone out. Thanks to the fact the UK generally doesn t have neutral wire in wall switches that means looking at something battery powered. Which means wifi based devices are a poor choice, and it s necessary to look at something lower power like Zigbee or Z-Wave.
Zigbee seems like the better choice; it s a more open standard and there are generally more devices easily available from what I ve seen (e.g. Philips Hue and IKEA TR DFRI). So I bought a couple of Xiaomi Mi Smart Home Wireless Switches, and a CC2530 module and then ignored it for the best part of a year. Finally I got around to flashing the Z-Stack firmware that Koen Kanters kindly provides. (Insert rant about hardware manufacturers that require pay-for tool chains. The CC2530 is even worse because it s 8051 based, so SDCC should be able to compile for it, but the TI Zigbee libraries are only available in a format suitable for IAR s embedded workbench.)
Flashing the CC2530 is a bit of faff. I ended up using the CCLib fork by Stephan Hadinger which supports the ESP8266. The nice thing about the CC2530 module is it has 2.54mm pitch pins so nice and easy to jumper up. It then needs a USB/serial dongle to connect it up to a suitable machine, where I ran Zigbee2MQTT. This scares me a bit, because it s a bunch of node.js pulling in a chunk of stuff off npm. On the flip side, it Just Works and I was able to pair the Xiaomi button with the device and see MQTT messages that I could then use with Home Assistant. So of course I tore down that setup and went and ordered a CC2531 (the variant with USB as part of the chip). The idea here was my test setup was upstairs with my laptop, and I wanted something hooked up in a more permanent fashion.
Once the CC2531 arrived I got distracted writing support for the Desk Viking to support CCLib (and modified it a bit for Python3 and some speed ups). I flashed the dongle up with the Z-Stack Home 1.2 (default) firmware, and plugged it into the house server. At this point I more closely investigated what Home Assistant had to offer in terms of Zigbee integration. It turns out the ZHA integration has support for the ZNP protocol that the TI devices speak (I m reasonably sure it didn t when I first looked some time ago), so that seemed like a better option than adding the MQTT layer in the middle.
I hit some complexity passing the dongle (which turns up as /dev/ttyACM0) through to the Home Assistant container. First I needed an override file in /etc/systemd/nspawn/hass.nspawn:
(I m not clear why the VirtualEthernet needed to exist; without it networking broke entirely but I couldn t see why it worked with no override file.)
A udev rule on the host to change the ownership of the device file so the root user and dialout group in the container could see it was also necessary, so into /etc/udev/rules.d/70-persistent-serial.rules went:
In the container itself I had to switch PrivateDevices=true to PrivateDevices=false in the home-assistant.service file (which took me a while to figure out; yay for locking things down and then needing to use those locked down things).
Finally I added the hass user to the dialout group. At that point I was able to go and add the integration with Home Assistant, and add the button as a new device. Excellent. I did find I needed a newer version of Home Assistant to get support for the button, however. I was still on 2021.1.5 due to upstream dropping support for Python 3.7 and not being prepared to upgrade to Debian 11 until it was actually released, so the version of zha-quirks didn t have the correct info. Upgrading to Home Assistant 2021.8.7 sorted that out.
There was another slight problem. Range. Really I want to use the button upstairs. The server is downstairs, and most of my internal walls are brick. The solution turned out to be a TR DFRI socket, which replaced the existing ESP8266 wifi socket controlling the stair lights. That was close enough to the server to have a decent signal, and it acts as a Zigbee router so provides a strong enough signal for devices upstairs. The normal approach seems to be to have a lot of Zigbee light bulbs, but I have mostly kept overhead lights as uncontrolled - we don t use them day to day and it provides a nice fallback if the home automation has issues.
Of course installing Zigbee for a single button would seem to be a bit pointless. So I ordered up a Sonoff door sensor to put on the front door (much smaller than expected - those white boxes on the door are it in the picture above). And I have a 4 gang wireless switch ordered to go on the landing wall upstairs.
Now I ve got a Zigbee setup there are a few more things I m thinking of adding, where wifi isn t an option due to the need for battery operation (monitoring the external gas meter springs to mind). The CC2530 probably isn t suitable for my needs, as I ll need to write some custom code to handle the bits I want, but there do seem to be some ARM based devices which might well prove suitable
After moving my Ikiwiki blog to my own server
and enabling a basic CSP policy, I decided to see if I could tighten up the
policy some more and stop relying on style-src 'unsafe-inline'.
This does require that OpenID logins be disabled, but as a bonus, it also
removes the need for jQuery to be present on the server.
Revised CSP policy
First of all, I visited all of my pages in a Chromium browser and took note
of the missing hashes listed in the developer tools console (Firefox
doesn't show the missing hashes):
which took care of all of the inline styles.
Note that I kept unsafe-inline in the directive since it will be
automatically ignored by browsers who understand hashes, but will be honored
and make the site work on older browsers.
Next I added the new
unsafe-hashes source
expression along with the hash of the CSS fragment (clear: both) that is
present on all pages related to comments in Ikiwiki:
Browser compatibility
While unsafe-hashes is not yet implemented in
Firefox, it happens
to work just fine due to a
bug (i.e.
unsafe-hashes is always enabled whether or not the policy contains it).
It's possible that my new CSP policy won't work in
Safari, but these CSS clears
don't appear to be needed anyways and so it's just going to mean extra CSP
reporting noise.
Removing jQuery
Since jQuery appears to only be used to provide the authentication system
selector UI, I decided to get rid of it.
I couldn't find a way to get Ikiwiki to stop pulling it in and so I put the
following hack in my Apache config file:
Replacing the files on disk with an empty reponse seems to work very well
and removes a whole lot of code that would otherwise be allowed by the
script-src directive of my CSP policy. While there is a slight cosmetic
change to the login page, I think the reduction in the attack surface is
well worth it.
8.5 years ago, I moved my
blog to
Ikiwiki and
Branchable. It's now time for me to take the
next step and host my blog on my own server. This is how I migrated from
Branchable to my own Apache server.
Installing Ikiwiki dependencies
Here are all of the extra Debian packages I had to install on my server:
and un-commented the following in /etc/apache2/mods-available/mime.conf:
AddHandler cgi-script .cgi
Creating a separate user account
Since Ikiwiki needs to regenerate my blog whenever a new article is pushed
to the git repo or a comment is accepted, I created a restricted user
account for it:
adduser blog
adduser blog sshuser
chsh -s /usr/bin/git-shell blog
git setup
Thanks to Branchable storing blogs in git repositories, I was able to import my
blog using a simple git clone in /home/blog (the srcdir):
Note that the name of the directory (source.git) is important for the
ikiwikihosting plugin to work.
Then I pulled the .setup file out of the setup branch in that repo and put
it in /home/blog/.ikiwiki/FeedingTheCloud.setup. After that, I deleted the
setup branch and the origin remote from that clone:
git branch -d setup
git remote rm origin
Following the recommended git
configuration, I created a working directory
(the repository) for the blog user to modify the blog as needed:
cd /home/blog/
git clone /home/blog/source.git FeedingTheCloud
I added my own ssh public key to /home/blog/.ssh/authorized_keys
so that I could push to the srcdir from my laptop.
Finaly, I generated a new ssh key without a passphrase:
One thing that failed to generate properly was the tag cloug (from the
pagestats plugin). I have not
been able to figure out why it fails to generate any output when run this
way, but if I push to the repo and let the git hook handle the rebuilding of
the wiki, the tag cloud is generated correctly. Consequently, fixing this
is not high on my list of priorities, but if you happen to know what the
problem is, please reach out.
Apache config
Here's the Apache config I put in /etc/apache2/sites-available/blog.conf:
a2ensite blog
apache2ctl configtest
systemctl restart apache2.service
The feeds.cloud.geek.nz domain used to be pointing to
Feedburner and so I need to
maintain it in order to avoid breaking RSS feeds from folks who added my
blog to their reader a long time ago.
Server-side improvements
Since I'm now in control of the server configuration, I was able to make
several improvements to how my blog is served.
First of all, I enabled the HTTP/2 and Brotli modules:
a2enmod http2
a2enmod brotli
and enabled Brotli
compression
by putting the following in /etc/apache2/conf-available/compression.conf:
Note that the Mozilla Observatory is mistakenly identifying HTTP onion
services as insecure, so you can ignore that failure.
I also used the Mozilla TLS config
generator
to improve the TLS config for my server.
Then I added security.txt and
gpc.json to the root
of my git repo and then added the following aliases to put these files in
the right place:
Alias /.well-known/gpc.json /var/www/blog/gpc.json
Alias /.well-known/security.txt /var/www/blog/security.txt
Monitoring 404s
Another advantage of running my own web server is that I can monitor the
404s easily using logcheck by
putting the following in /etc/logcheck/logcheck.logfiles:
/var/log/apache2/blog-error.log
Based on that, I added a few redirects to point bots and users to the
location of my RSS feed:
Future improvements
There are a few things I'd like to improve on my current setup.
The first one is to remove the iwikihosting and gitpush
plugins and replace them with a
small script which would simply git push to the read-only GitHub mirror.
Then I could uninstall the ikiwiki-hosting-common and
ikiwiki-hosting-web
since that's all I use them for.
Next, I would like to have proper support for signed git
pushes. At the
moment, I have the following in /home/blog/source.git/config:
but I'd like to also reject unsigned pushes.
While my blog now has a CSP policy which doesn't rely on unsafe-inline for
scripts, it does rely on unsafe-inline for stylesheets. I tried to remove this
but the actual calls to allow seemed to be located deep within jQuery and so I gave up.
Update: now fixed.
Finally, I'd like to figure out a good way to deal with articles which don't
currently have comments. At the moment, if you try to subscribe to their
comment feed, it returns a 404. For example:
[Sun Jun 06 17:43:12.336350 2021] [core:info] [pid 30591:tid 140253834704640] [client 66.249.66.70:57381] AH00128: File does not exist: /var/www/blog/posts/using-iptables-with-network-manager/comments.atom
This is obviously not ideal since many feed readers will refuse to add a
feed which is currently not found even though it could become real in the future. If
you know of a way to fix this, please let me know.
In the past, I've talked about building a Z80-based computer. I made some progress towards that goal, in the sense that I took the initial (trivial steps) towards making something:
I built a clock-circuit.
I wired up a Z80 processor to the clock.
I got the thing running an endless stream of NOP instructions.
No RAM/ROM connected, tying all the bus-lines low, meaning every attempted memory-read returned 0x00 which is the Z80 NOP instruction.
But then I stalled, repeatedly, at designing an interface to RAM and ROM, so that it could actually do something useful. Over the lockdown I've been in two minds about getting sucked back down the rabbit-hole, so I compromised. I did a bit of searching on tindie, and similar places, and figured I'd buy a Z80-based single board computer. My requirements were minimal:
It must run CP/M.
The source-code to "everything" must be available.
I want it to run standalone, and connect to a host via a serial-port.
With those goals there were a bunch of boards to choose from, rc2014 is the standard choice - a well engineered system which uses a common backplane and lets you build mini-boards to add functionality. So first you build the CPU-card, then the RAM card, then the flash-disk card, etc. Over-engineered in one sense, extensible in another. (There are some single-board variants to cut down on soldering overhead, at a cost of less flexibility.)
After a while I came across https://8bitstack.co.uk/, which describes a simple board called the the Z80 playground.
The advantage of this design is that it loads code from a USB stick, making it easy to transfer files to/from it, without the need for a compact flash card, or similar. The downside is that the system has only 64K RAM, meaning it cannot run CP/M 3, only 2.2. (CP/M 3.x requires more RAM, and a banking/paging system setup to swap between pages.)
When the system boots it loads code from an EEPROM, which then fetches the CP/M files from the USB-stick, copies them into RAM and executes them. The memory map can be split so you either have ROM & RAM, or you have just RAM (after the boot the ROM will be switched off). To change the initial stuff you need to reprogram the EEPROM, after that it's just a matter of adding binaries to the stick or transferring them over the serial port.
In only a couple of hours I got the basic stuff working as well as I needed:
A z80-assembler on my Linux desktop to build simple binaries.
An installation of Turbo Pascal 3.00A on the system itself.
The Zork trilogy installed, along with Hitchhikers guide.
I had some fun with a CP/M emulator to get my hand back in things before the board arrived, and using that I tested my first "real" assembly language program (cls to clear the screen), as well as got the hang of using the wordstar keyboard shortcuts as used within the turbo pascal environment.
I have some plans for development:
Add command-line history (page-up/page-down) for the CP/M command-processor.
Add paging to TYPE, and allow terminating with Q.
Nothing major, but fun changes that won't be too difficult to implement.
Since CP/M 2.x has no concept of sub-directories you end up using drives for everything, I implemented a "search-path" so that when you type "FOO" it will attempt to run "A:FOO.COM" if there is no file matching on the current-drive. That's a nicer user-experience at all.
I also wrote some Z80-assembly code to search all drives for an executable, if not found in current drive and not already qualified. Remember CP/M doesn't have a concept of sub-directories) that's actually pretty useful:
B>LOCATE H*.COM
P:HELLO COM
P:HELLO2 COM
G:HITCH COM
E:HYPHEN COM
I've also written some other trivial assembly language tools, which was surprisingly relaxing. Especially once I got back into the zen mode of optimizing for size.
I forked the upstream repository, mostly to tidy up the contents, rather than because I want to go into my own direction. I'll keep the contents in sync, because there's no point splitting a community even further - I guess there are fewer than 100 of these boards in the wild, probably far far fewer!
Host to Kanchenjunga, the world s third-highest mountain peak and the endangered Red Panda, Sikkim is a state in northeastern India. Nestled between Nepal, Tibet (China), Bhutan and West Bengal (India), the state offers a smorgasbord of cultures and cuisines. That said, it s hardly surprising that the old spice route meanders through western Sikkim, connecting Lhasa with the ports of Bengal. Although the latter could also be attributed to cardamom (kali elaichi), a perennial herb native to Sikkim, which the state is the second-largest producer of, globally. Lastly, having been to and lived in India, all my life, I can confidently say Sikkim is one of the cleanest & safest regions in India, making it ideal for first-time backpackers.
Brief History
17th century: The Kingdom of Sikkim is founded by the Namgyal dynasty and ruled by Buddhist priest-kings known as the Chogyal.
1890: Sikkim becomes a princely state of British India.
1947: Sikkim continues its protectorate status with the Union of India, post-Indian-independence.
1973: Anti-royalist riots take place in front of the Chogyal's palace, by Nepalis seeking greater representation.
1975: Referendum leads to the deposition of the monarchy and Sikkim joins India as its 22nd state.
Languages
Official: English, Nepali, Sikkimese/Bhotia and Lepcha
Though Hindi and Nepali share the same script (Devanagari), they are not mutually intelligible. Yet, most people in Sikkim can understand and speak Hindi.
Ethnicity
Nepalis: Migrated in large numbers (from Nepal) and soon became the dominant community
Bhutias: People of Tibetan origin. Major inhabitants in Northern Sikkim.
Lepchas: Original inhabitants of Sikkim
Food
Tibetan/Nepali dishes (mostly consumed during winter)
Thukpa: Noodle soup, rich in spices and vegetables. Usually contains some form of meat. Common variations: Thenthuk and Gyathuk
Momos: Steamed or fried dumplings, usually with a meat filling.
Saadheko: Spicy marinated chicken salad.
Gundruk Soup: A soup made from Gundruk, a fermented leafy green vegetable.
Sinki : A fermented radish tap-root product, traditionally consumed as a base for soup and as a pickle. Eerily similar to Kimchi.
While pork and beef are pretty common, finding vegetarian dishes is equally easy.
Staple: Dal-Bhat with Subzi. Rice is a lot more common than wheat (rice) possibly due to greater carb content and proximity to West Bengal, India s largest producer of Rice.
Good places to eat in Gangtok
Hamro Bhansa Ghar, Nimtho (Nepali)
Taste of Tibet
Dragon Wok (Chinese & Japanese)
Buddhism in Sikkim
Bayul Demojong (Sikkim), is the most sacred Land in the Himalayas as per the belief of the Northern Buddhists and various religious texts.
Sikkim was blessed by Guru Padmasambhava, the great Buddhist saint who visited Sikkim in the 8th century and consecrated the land.
However, Buddhism is said to have reached Sikkim only in the 17th century with the arrival of three Tibetan monks viz. Rigdzin Goedki Demthruchen, Mon Kathok Sonam Gyaltshen & Rigdzin Legden Je at Yuksom. Together, they established a Buddhist monastery.
In 1642 they crowned Phuntsog Namgyal as the first monarch of Sikkim and gave him the title of Chogyal, or Dharma Raja.
The faith became popular through its royal patronage and soon many villages had their own monastery.
Today Sikkim has over 200 monasteries.
Major monasteries
Rumtek Monastery, 20Km from Gangtok
Lingdum/Ranka Monastery, 17Km from Gangtok
Phodong Monastery, 28Km from Gangtok
Ralang Monastery, 10Km from Ravangla
Tsuklakhang Monastery, Royal Palace, Gangtok
Enchey Monastery, Gangtok
Tashiding Monastery, 35Km from Ravangla
Reaching Sikkim
Gangtok, being the capital, is easiest to reach amongst other regions, by public transport and shared cabs.
About 20 minutes from Siliguri and 4 hours from Gangtok.
Reserved cabs cost about INR 3000. Shared cabs from INR 350.
By Road:
NH10 connects Siliguri to Gangtok
If you can t find buses plying to Gangtok directly, reach Siliguri and then take a cab to Gangtok.
Sikkim Nationalised Transport Div. also runs hourly buses between Siliguri and Gangtok and daily buses on other common routes. They re cheaper than shared cabs.
Wizzride also operates shared cabs between Siliguri/Bagdogra/NJP, Gangtok and Darjeeling. They cost about the same as shared cabs but pack in half as many people in luxury cars (Innova, Xylo, etc.) and are hence more comfortable.
The easiest & most economical way to explore North Sikkim is the 3D/2N package offered by shared-cab drivers.
This includes food, permits, cab rides and accommodation (1N in Lachen and 1N in Lachung)
The accommodation on both nights are at homestays with bare necessities, so keep your hopes low.
In the spirit of sustainable tourism, you ll be asked to discard single-use plastic bottles, so please carry a bottle that you can refill along the way.
Zero Point and Gurdongmer Lake are snow-capped throughout the year
3D/2N Shared-cab Package Itinerary
Day 1
Gangtok (10am) - Chungthang - Lachung (stay)
Day 2
Pre-lunch : Lachung (6am) - Yumthang Valley [12,139ft] - Zero Point - Lachung [15,300ft]
Post-lunch : Lachung - Chungthang - Lachen (stay)
Day 3
Pre-lunch : Lachen (5am) - Kala Patthar - Gurdongmer Lake [16,910ft] - Lachen
Post-lunch : Lachen - Chungthang - Gangtok (7pm)
This itinerary is idealistic and depends on the level of snowfall.
Some drivers might switch up Day 2 and 3 itineraries by visiting Lachen and then Lachung, depending upon the weather.
Areas beyond Lachen & Lachung are heavily militarized since the Indo-China border is only a few miles away.
East Sikkim
Zuluk and Silk Route
Time needed: 2D/1N
Zuluk [9,400ft] is a small hamlet with an excellent view of the eastern Himalayan range including the Kanchenjunga.
Was once a transit point to the historic Silk Route from Tibet (Lhasa) to India (West Bengal).
The drive from Gangtok to Zuluk takes at least four hours. Hence, it makes sense to spend the night at a homestay and space out your trip to Zuluk
Tsomgo Lake and Nathula
Time Needed : 1D
A Protected Area Permit is required to visit these places, due to their proximity to the Chinese border
Located on the Indo-Tibetan border crossing of the Old Silk Route, it is one of the three open trading posts between India and China.
Plays a key role in the Sino-Indian Trade and also serves as an official Border Personnel Meeting(BPM) Point.
May get cordoned off by the Indian Army in event of heavy snowfall or for other security reasons.
West Sikkim
Time needed: 3N/1N
Hostels at Pelling : Mochilerro Ostillo
Itinerary
Day 1: Gangtok - Ravangla - Pelling
Leave Gangtok early, for Ravangla through the Temi Tea Estate route.
Spend some time at the tea garden and then visit Buddha Park at Ravangla
Head to Pelling from Ravangla
Day 2: Pelling sightseeing
Hire a cab and visit Skywalk, Pemayangtse Monastery, Rabdentse Ruins, Kecheopalri Lake, Kanchenjunga Falls.
Day 3: Pelling - Gangtok/Siliguri
Wake up early to catch a glimpse of Kanchenjunga at the Pelling Helipad around sunrise
Head back to Gangtok on a shared-cab
You could take a bus/taxi back to Siliguri if Pelling is your last stop.
Darjeeling
In my opinion, Darjeeling is lovely for a two-day detour on your way back to Bagdogra/Siliguri and not any longer (unless you re a Bengali couple on a honeymoon)
Once a part of Sikkim, Darjeeling was ceded to the East India Company after a series of wars, with Sikkim briefly receiving a grant from EIC for gifting Darjeeling to the latter
Post-independence, Darjeeling was merged with the state of West Bengal.
Reach Darjeeling by noon and check in to your Hostel. I stayed at Hideout.
Spend the evening visiting either a monastery (or the Batasia Loop), Nehru Road and Mall Road.
Grab dinner at Glenary whilst listening to live music.
Day 2:
Wake up early to catch the sunrise and a glimpse of Kanchenjunga at Tiger Hill. Since Tiger Hill is 10km from Darjeeling and requires a permit, book your taxi in advance.
Alternatively, if you don t want to get up at 4am or shell out INR1500 on the cab to Tiger Hill, walk to the Kanchenjunga View Point down Mall Road
Next, queue up outside Keventers for breakfast with a view in a century-old cafe
Get a cab at Gandhi Road and visit a tea garden (Happy Valley is the closest) and the Ropeway. I was lucky to meet 6 other backpackers at my hostel and we ended up pooling the cab at INR 200 per person, with INR 1400 being on the expensive side, but you could bargain.
Get lunch, buy some tea at Golden Tips, pack your bags and hop on a shared-cab back to Siliguri. It took us about 4hrs to reach Siliguri, with an hour to spare before my train.
If you ve still got time on your hands, then check out the Peace Pagoda and the Darjeeling Himalayan Railway (Toy Train). At INR 1500, I found the latter to be too expensive and skipped it.
Tips and hacks
Download offline maps, especially when you re exploring Northern Sikkim.
Food and booze are the cheapest in Gangtok. Stash up before heading to other regions.
In rural areas and some cafes, you may get to try Rhododendron Wine, made from Rhododendron arboreum a.k.a Gurans. Its production is a little hush-hush since the flower is considered holy and is also the National Flower of Nepal.
If you don t want to invest in a new jacket, boots or a pair of gloves, you can always rent them at nominal rates from your hotel or little stores around tourist sites.
Check the weather of a region before heading there. Low visibility and precipitation can quite literally dampen your experience.
Keep your itinerary flexible to accommodate for rest and impromptu plans.
Shops and restaurants close by 8pm in Sikkim and Darjeeling. Plan for the same.
Carry
a couple of extra pairs of socks (woollen, if possible)
a pair of slippers to wear indoors
a reusable water bottle
an umbrella
a power bank
a couple of tablets of Diamox. Helps deal with altitude sickness
extra clothes and wet bags since you may not get a chance to wash/dry your clothes
a few passport size photographs
Shared-cab hacks
Intercity rides can be exhausting. If you can afford it, pay for an additional seat.
Call shotgun on the drives beyond Lachen and Lachung. The views are breathtaking.
Return cabs tend to be cheaper (WB cabs travelling from SK and vice-versa)
Cost
My median daily expenditure (back when I went to Sikkim in early March 2021) was INR 1350.
This includes stay (bunk bed), food, wine and transit (shared cabs)
In my defence, I splurged on food, wine and extra seats in shared cabs, but if you re on a budget, you could easily get by on INR 1 - 1.2k per day.
For a 9-day trip, I ended up shelling out nearly INR 15k, including 2AC trains to & from Kolkata
Note : Summer (March to May) and Autumn (October to December) are peak seasons, and thereby more expensive to travel around.
Souvenirs and things you should buy
Buddhist souvenirs :
Colourful Prayer Flags (great for tying on bikes or behind car windshields)
Miniature Prayer/Mani Wheels
Lucky Charms, Pendants and Key Chains
Cham Dance masks and robes
Singing Bowls
Common symbols: Om mani padme hum, Ashtamangala, Zodiac signs
How our for-profit company became a nonprofit, to better tackle the digital divide.
Originally posted on the Endless OS Foundation blog.
An 8-year journey to a nonprofit
On the 1st of April 2020, our for-profit Endless Mobile officially became a nonprofit as the Endless OS Foundation. Our launch as a nonprofit just as the global pandemic took hold was, predictably, hardly noticed, but for us the timing was incredible: as the world collectively asked What can we do to help others in need? , we framed our mission statement and launched our .org with the same very important question in mind. Endless always had a social impact mission at its heart, and the challenges related to students, families, and communities falling further into the digital divide during COVID-19 brought new urgency and purpose to our team s decision to officially step in the social welfare space.
On April 1st 2020, our for-profit Endless Mobile officially became a nonprofit as the Endless OS Foundation, focused on the #DigitalDivide.
Our updated status was a long time coming: we began our transformation to a nonprofit organization in late 2019 with the realization that the true charter and passions of our team would be greatly accelerated without the constraints of for-profit goals, investors and sales strategies standing in the way of our mission of digital access and equity for all.
But for 8 years we made a go of it commercially, headquartered in Silicon Valley and framing ourselves as a tech startup with access to the venture capital and partnerships on our doorstep. We believed that a successful commercial channel would be the most efficient way to scale the impact of bringing computer devices and access to communities in need. We still believe this we ve just learned through our experience that we don t have the funding to enter the computer and OS marketplace head-on. With the social impact goal first, and the hope of any revenue a secondary goal, we have had many successes in those 8 years bridging the digital divide throughout the world, from Brazil, to Kenya, and the USA. We ve learned a huge amount which will go on to inform our strategy as a nonprofit.
Endless always had a social impact mission at its heart. COVID-19 brought new urgency and purpose to our team s decision to officially step in the social welfare space.
Our unique perspective
One thing we learned as a for-profit is that the OS and technology we ve built has some unique properties which are hugely impactful as a working solution to digital equity barriers. And our experience deploying in the field around the world for 8 years has left us uniquely informed via many iterations and incremental improvements.
With this knowledge in-hand, we ve been refining our strategy throughout 2020 and now starting to focus on what it really means to become an effective nonprofit and make that impact. In many ways it is liberating to abandon the goals and constraints of being a for-profit entity, and in other ways it s been a challenging journey for me and the team to adjust our way of thinking and let these for-profit notions and models go. Previously we exclusively built and sold a product that defined our success; and any impact we achieved was a secondary consequence of that success and seen through that lens. Now our success is defined purely in terms of social impact, and through our actions, those positive impacts can be made with or without our product . That means that we may develop and introduce technology to solve a problem, but it is equally as valid to find another organization s existing offering and design a way to increase that positive impact and scale.
We develop technology to solve access equity issues, but it s equally as valid to find another organization s offering and partner in a way that increases their positive impact.
The analogy to Free and Open Source Software is very strong while Endless has always used and contributed to a wide variety of FOSS projects, we ve also had a tension where we ve been trying to hold some pieces back and capture value such as our own application or content ecosystem, our own hardware platform necessarily making us competitors to other organisations even though they were hoping to achieve the same things as us. As a nonprofit we can let these ideas go and just pick the best partners and technologies to help the people we re trying to reach.
Digital equity 4 barriers we need to overcome
In future, our decisions around which projects to build or engage with will revolve around 4 barriers to digital equity, and how our Endless OS, Endless projects, or our partners offerings can help to solve them. We define these 4 equity barriers as: barriers to devices, barriers to connectivity, barriers to literacy in terms of your ability to use the technology, and barriers to engagement in terms of whether using the system is rewarding and worthwhile.
We define the 4 digital equity barriers we exist to impact as: 1. barriers to devices 2. barriers to connectivity 3. barriers to literacy 4. barriers to engagement
It doesn t matter who makes the solutions that break these barriers; what matters is how we assist in enabling people to use technology to gain access to the education and opportunities these barriers block. Our goal therefore is to simply ensure that solutions exist building them ourselves and with partners such as the FOSS community and other nonprofits proving them with real-world deployments, and sharing our results as widely as possible to allow for better adoption globally.
If we define our goal purely in terms of whether people are using Endless OS, we are effectively restricting the reach and scale of our solutions to the audience we can reach directly with Endless OS downloads, installs and propagation. Conversely, partnerships that scale impact are a win-win-win for us, our partners, and the communities we all serve.
Engineering impact
Our Endless engineering roots and capabilities feed our unique ability to build and deploy all of our solutions, and the practical experience of deploying them gives us evidence and credibility as we advocate for their use. Either activity would be weaker without the other.
Our engineering roots and capabilities feed our unique ability to build and deploy digital divide solutions.
Our partners in various engineering communities will have already seen our change in approach. Particularly, with GNOME we are working hard to invest in upstream and reconcile the long-standing differences between our experience and GNOME. If successful, many more people can benefit from our work than just users of Endless OS. We re working with Learning Equality on Kolibri to build a better app experience for Linux desktop users and bring content publishers into our ecosystem for the first time, and we ve also taken our very own Hack, the immersive and fun destination for kids learning to code, released it for non-Endless systems on Flathub, and made it fully open-source.
What s next for our OS?
What then is in store for the future of Endless OS, the place where we have invested so much time and planning through years of iterations? For the immediate future, we need the capacity to deploy everything we ve built all at once, to our partners. We built an OS that we feel is very unique and valuable, containing a number of world-firsts: first production OS shipped with OSTree, first Flatpak-only desktop, built-in support for updating OS and apps from USBs, while still providing a great deal of reliability and convenience for deployments in offline and educational-safe environments with great apps and content loaded on every system.
However, we need to find a way to deliver this Linux-based experience in a more efficient way, and we d love to talk if you have ideas about how we can do this, perhaps as partners. Can the idea of Endless OS evolve to become a spec that is provided by different platforms in the future, maybe remixes of Debian, Fedora, openSUSE or Ubuntu?
Build, Validate, Advocate
Beyond the OS, the Endless OS Foundation has identified multiple programs to help underserved communities, and in each case we are adopting our build, validate, advocate strategy. This approach underpins all of our projects: can we build the technology (or assist in the making), will a community in-need validate it by adoption, and can we inspire others by telling the story and advocating for its wider use?
We are adopting a build, validate, advocate strategy. 1. build the technology (or assist in the making) 2. validate by community adoption 3. advocate for its wider use
As examples, we have just launched the Endless Key (link) as an offline solution for students during the COVID-19 at-home distance learning challenges. This project is also establishing a first-ever partnership of well-known online educational brands to reach an underserved offline audience with valuable learning resources. We are developing a pay-as-you-go platform and new partnerships that will allow families to own laptops via micro-payments that are built directly into the operating system, even if they cannot qualify for standard retail financing. And during the pandemic, we ve partnered with Teach For America to focus on very practical digital equity needs in the USA s urban and rural communities.
One part of the world-wide digital divide solution
We are one solution provider for the complex matrix of issues known collectively as the #DigitalDivide, and these issues will not disappear after the pandemic. Digital equity was an issue long before COVID-19, and we are not so naive to think it can be solved by any single institution, or by the time the pandemic recedes. It will take time and a coalition of partnerships to win. We are in for the long-haul and we are always looking for partners, especially now as we are finding our feet in the nonprofit world. We d love to hear from you, so please feel free to reach out to me I m ramcq on IRC, RocketChat, Twitter, LinkedIn or rob@endlessos.org.
in order to create a version 3 onion
service without
actually running a Tor relay.
Note that since I am making a public website available over Tor, I do not
need the location of the website to be hidden and so I used the same
settings as
Cloudflare in their
public Tor proxy.
Also, I explicitly used the external IPv6 address of my server in the
configuration in order to prevent localhost
bypasses.
After restarting the Tor daemon to reload the configuration file:
Apache configuration
Next, I enabled a few required Apache modules:
a2enmod mpm_event
a2enmod http2
a2enmod headers
and configured my Apache vhosts in /etc/apache2/sites-enabled/www.conf:
<VirtualHost *:443>
ServerName fmarier.org
ServerAlias ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Protocols h2, http/1.1
Header set Onion-Location "http://ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion% REQUEST_URI s"
Header set alt-svc 'h2="ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion:443"; ma=315360000; persist=1'
Header add Strict-Transport-Security: "max-age=63072000"
Include /etc/fmarier-org/www-common.include
SSLEngine On
SSLCertificateFile /etc/letsencrypt/live/fmarier.org/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/fmarier.org/privkey.pem
</VirtualHost>
<VirtualHost *:80>
ServerName fmarier.org
Redirect permanent / https://fmarier.org/
</VirtualHost>
<VirtualHost *:80>
ServerName ixrdj3iwwhkuau5tby5jh3a536a2rdhpbdbu6ldhng43r47kim7a3lid.onion
Include /etc/fmarier-org/www-common.include
</VirtualHost>
Note that /etc/fmarier-org/www-common.include contains all of the
configuration options that are common to both the HTTP and the HTTPS sites
(e.g. document root, caching headers, aliases, etc.).
Finally, I restarted Apache:
$ whois 2a0b:f4c2:2::1
...
inet6num: 2a0b:f4c2::/40
netname: MK-TOR-EXIT
remarks: -----------------------------------
remarks: This network is used for Tor Exits.
remarks: We do not have any logs at all.
remarks: For more information please visit:
remarks: https://www.torproject.org
which indicates that the first request was not using the .onion
address.
The second IP address is the one for my server:
 In my two most recent posts, I listed the fiction and classic fiction I enjoyed the most in 2022.
I'll leave my roundup of general non-fiction until tomorrow, but today I'll be going over my favourite memoirs and biographies, in no particular order.
Books that just missed the cut here include Roisin Kiberd's The Disconnect: A Personal Journey Through the Internet (2019), Steve Richards' The Prime Ministers (2019) which reflects on UK leadership from Harold Wilson to Boris Johnson, Robert Graves Great War memoir Goodbye to All That (1929) and David Mikics's portrait of Stanley Kubrick called American Filmmaker.
In my two most recent posts, I listed the fiction and classic fiction I enjoyed the most in 2022.
I'll leave my roundup of general non-fiction until tomorrow, but today I'll be going over my favourite memoirs and biographies, in no particular order.
Books that just missed the cut here include Roisin Kiberd's The Disconnect: A Personal Journey Through the Internet (2019), Steve Richards' The Prime Ministers (2019) which reflects on UK leadership from Harold Wilson to Boris Johnson, Robert Graves Great War memoir Goodbye to All That (1929) and David Mikics's portrait of Stanley Kubrick called American Filmmaker.
 By sheer chance, I actually visited this exact garden immediately to the publication of this book
By sheer chance, I actually visited this exact garden immediately to the publication of this book









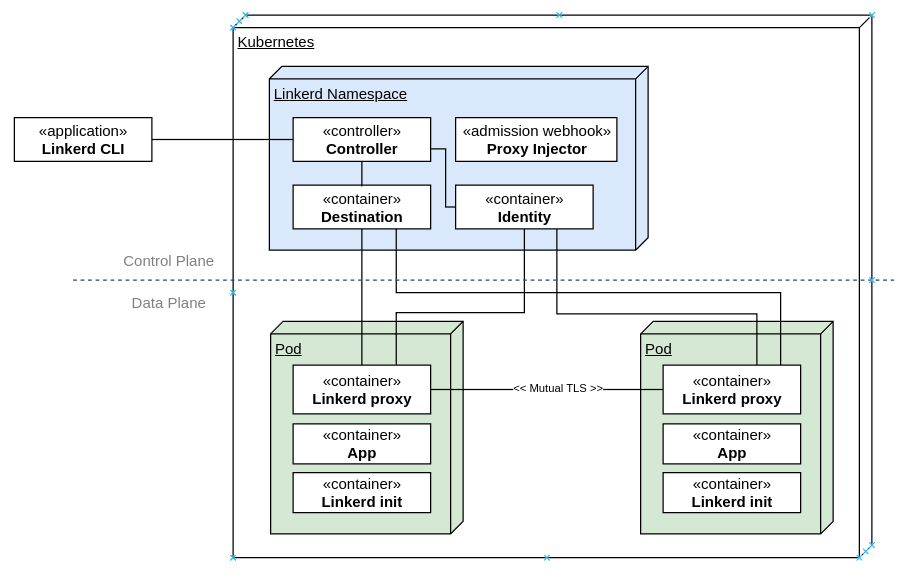
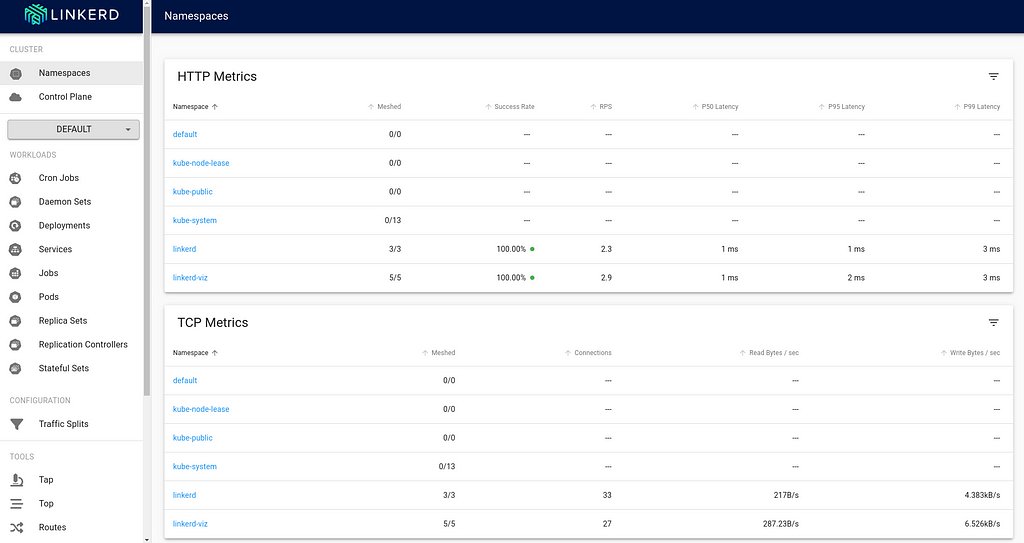
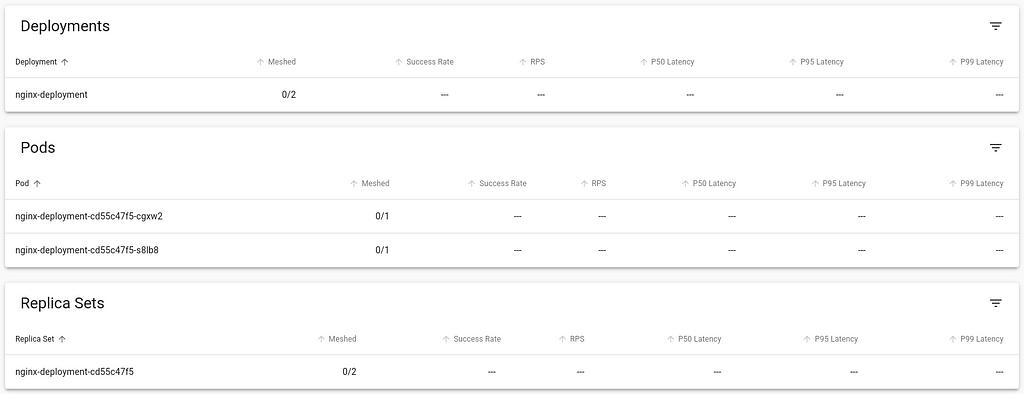
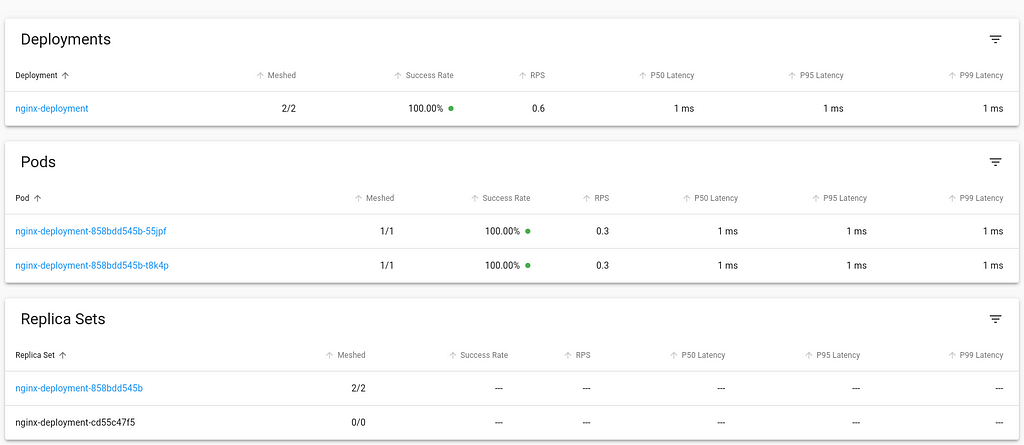
 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: 
 . The system talks about a back key but what back key I have no clue.
. The system talks about a back key but what back key I have no clue.
 Among my collection of PC hardware, I have a few rarities whose netboot implementation predates PXE. Since I recently managed to configure dnsmasq as a potent TFTP and PXE server, I figured that I'd try chainloading iPXE via BOOTP options. This required preparing a boot image using antiquated tools:
Among my collection of PC hardware, I have a few rarities whose netboot implementation predates PXE. Since I recently managed to configure dnsmasq as a potent TFTP and PXE server, I figured that I'd try chainloading iPXE via BOOTP options. This required preparing a boot image using antiquated tools:


 The
The 
 My
My  In the past, I've talked about building a Z80-based computer. I made some progress towards that goal, in the sense that I took the initial (trivial steps) towards making something:
In the past, I've talked about building a Z80-based computer. I made some progress towards that goal, in the sense that I took the initial (trivial steps) towards making something:


















 Testing that the
Testing that the {kind=link}